- 본 게시글은 Justin Johnson 교수님의 Deep Learning for Computer Vision, University of Michigan 정리글입니다.
- 개인적인 생각이 서술되어 있습니다. 잘못된 내용이 존재할 확률이 존재하기에 주의 바랍니다.
- 잘못된 내용, 오타는 지적해 주시면 감사하겠습니다.
강의링크:
https://www.youtube.com/watch?v=WUazOtlti0g&list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r&index=11
강의자료:
https://web.eecs.umich.edu/~justincj/slides/eecs498/498_FA2019_lecture11.pdf
Learning Rate Schedules
모든 optimizer들은 learning rate(학습률)을 하이퍼파라미터로 지닙니다. 그리고 시간(or epoch)에 따라 learning rate에 변화를 주는 것을 learning rate schedules라고 합니다.

learning rate의 크기에 따라 epoch가 진행될수록 양상이 달라집니다. 너무 크면 loss가 발산할 수 있고, 작다면 수렴하는데 시간이 많이 걸릴 수 있습니다. 따라서 적절한 learning rate 설정이 중요합니다. 그럼 몇 가지 Learning rate decay 방법 & Constant를 살펴보겠습니다.
Learning Rate Decay: Step
Step은 일정 Epoch마다 learning rate를 낮추는 방법입니다. 예를 들어 ResNet의 경우 Epoch가 30번 진행될 때마다 학습률을 1 / 10으로 낮춥니다. 하지만 epoch 몇 번 당 학습률을 낮출지, 어느 정도 낮출지 등 하이퍼파라미터를 결정해야 하는 어려움이 있습니다.
Learning Rate Decay: Cosine
Cosine은 Cosine 함수를 따르는 deacy 방법입니다. Cosine에서 설정하여야 할 하이퍼파라미터는 2개밖에 없습니다. 그리고 이 2개는 다른 방법에서도 사용되기에 하이퍼파라미터가 가장 적은 방법입니다.
- Initial learning rate, 알파
- # of epoch, T
Learning Rate Decay: Linear
Cosine과 Linear 중 뭐가 좋다고 말할 수는 없지만, cosine은 computer vision, linear은 NLP에서 주로 사용된다.
Learning Rate Decay: Inverse Sqrt
잘 사용되지 않는 방법입니다.
Constant
가장 많이 사용되고 추천되는 방법입니다.
지금까지 다양한 learning rate 방법들을 살펴보았는데요, 어떤 방법을 선택할지는 optimizer에 따라 다릅니다. SGD with momentum은 learning rate decay를 사용하는 게 좋지만 rmsprop, adam과 같은 복잡한 optimizer에서는 constant learning rate를 사용하는 게 좋습니다.
Early Stopping
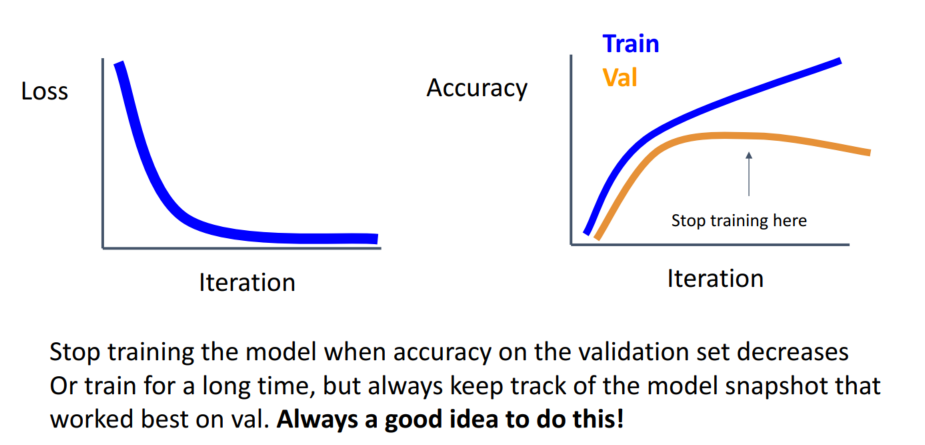
Iteration, Epoch가 증가할수록 Train data에 관한 오차는 작아지지만, Overfitting으로 인해 모델의 일반화 성능이 떨어질 수 있습니다. 이때 Early Stopping을 사용합니다. Early Stopping은 validation loss가 증가, accuracy가 감소할 때 멈추는 방법입니다. 이때 주의할 점은 직전의 epoch와만 비교해서는 안 된다는 점입니다. Accuracy가 증가추세라도 각 epoch들은 올라갔다 내려갔다를 반복하기에 일정한 epoch동안 계속해서 validation loss가 증가할 때 학습을 중단해야 합니다.
Choosing Hyperparameters
Grid Search는 가능한 모든 선택지들을 검증하는 방법입니다. 이는 계산비용이 많이 듭니다. Random Search는 random 하게 값들을 선정하여 진행하는 방법입니다.
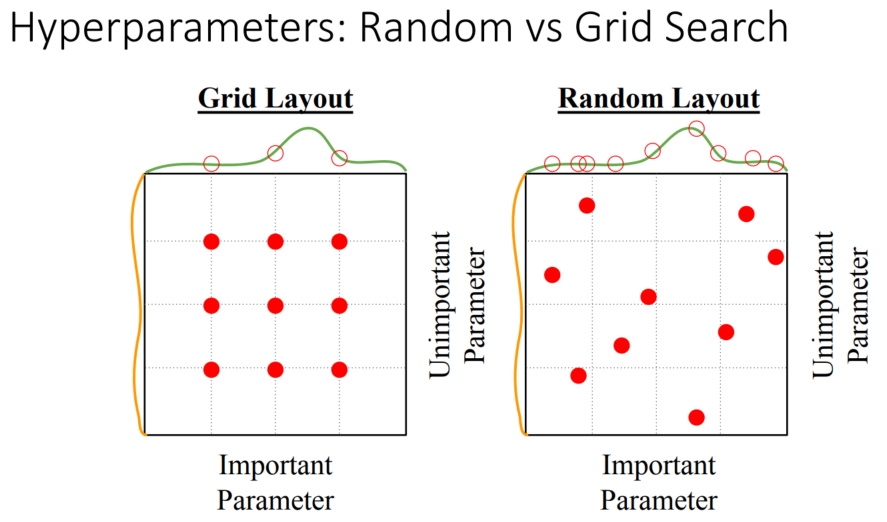
Random Search는 Grid Search에 비해 다양한 point들을 탐색하기에, 좋은 point들을 선택할 확률이 높습니다. Grid Search는 Grid 위에 있는 point들만 탐색하고, 또한 이 point들을 모두 탐색하여야 하기에 연산 비용이 큽니다. 반면 Random Search는 연산 시간이 적고, 더 좋은 성능을 발휘할 확률이 큽니다. 그러나 Random Search 또한 단점이 있습니다. 단순히 정해진 구간 안에서만 Random 하게 point를 추출하기에, 나온 결과들을 반영하지 않습니다. 이는 Bayesian optimization을 사용하여야 합니다.
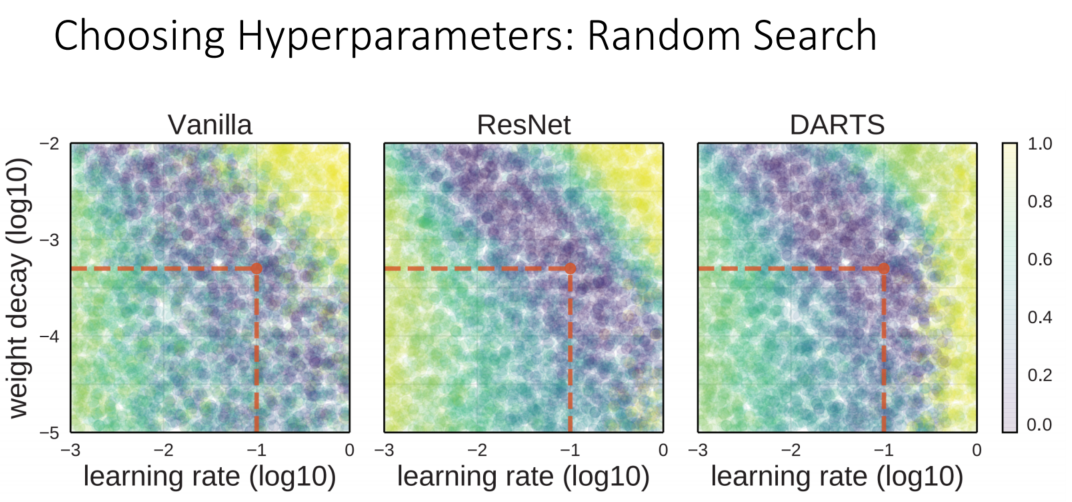
Random Search를 사용할 수 있다면 좋겠지만, GPU가 많이 필요합니다. Facebook처럼 GPU를 많이 사용가능하다면 Random Search를 진행해도 괜찮지만, 대부분은 그렇지 않기에 이어지는 7가지 Step을 통해 하이퍼파라미터를 설정합니다.
Step 1: Check initial loss
Weight decay를 적용하지 않은 상태에서 Loss 함수의 구조를 파악합니다.
Step 2: Overfit a small sample
작은 sample을 통해 training accuracy를 검증해 봅니다. 구조가 올바르게 작동하는지 확인하는 것이 목적이며, 만약 작은 sample에서도 overfitting 되지 않는다면 규모가 큰 training data에서는 fitting이 되지 않을 것임을 전제합니다.
Step 3: Find LR that makes loss go down
Step 2에서 이미 좋은 구조를 찾았기에 모든 training data를 사용하여 loss를 빠르게 떨어뜨리는 learning rate를 선정합니다.
Step 4: Coarse grid, train for ~1-5 epochs
몇 개의 모델에 학습률과 weight decay를 적용하여 1~5회 epcoh를 학습해 봅니다.
Step 5: Refine grid, train longer
Step 4에서 가장 성능이 좋은 모델을 learning rate decay 없이 10~20회 epoch를 학습해 봅니다.
Step 6: Look at loss curves
Step 5에서 학습한 모델의 Learning curve를 살펴봅니다.
Step 7: GOTO step 5
몇몇 그래프를 통해 어떤 문제가 있는지 확인해 보겠습니다.
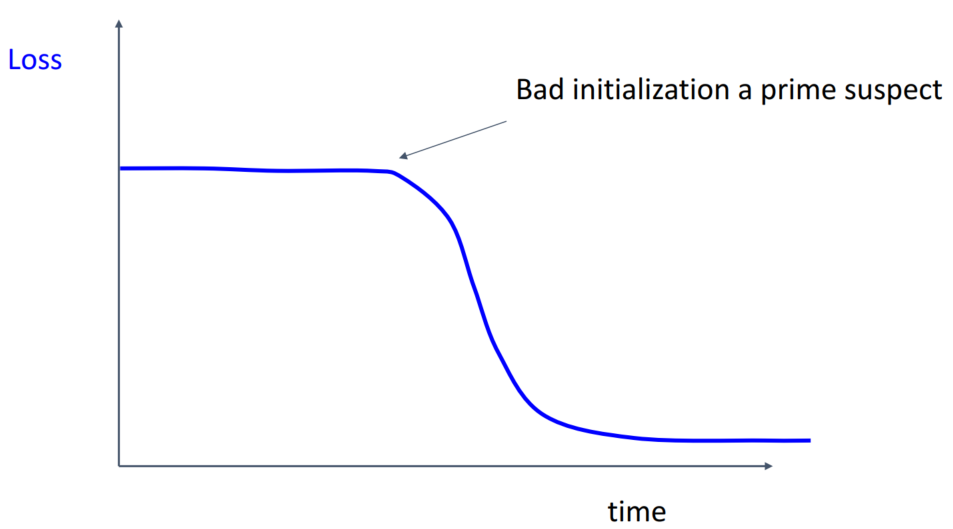
초반에 loss가 감소하지 않고 있습니다. 이는 initialization이 잘못 설정되었음을 의미합니다.
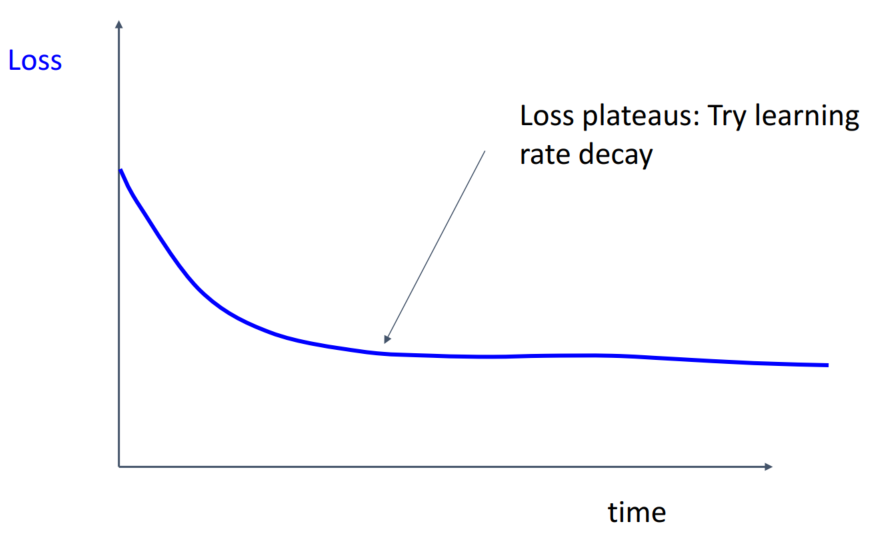
이번 글의 맨 처음에 등장하였던 high learning rate의 양상과 비슷합니다. learning rate decay를 통해 학습률을 조정할 필요성이 있습니다.
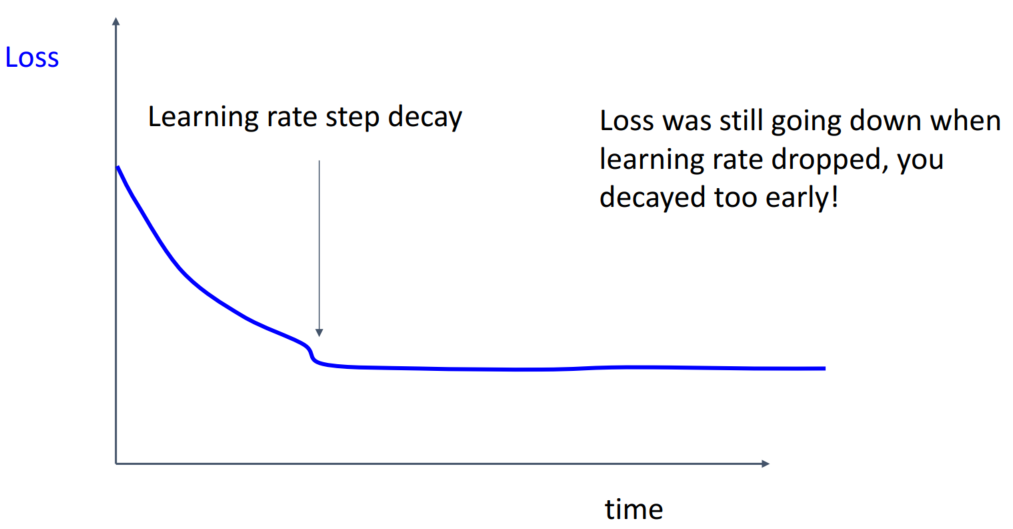
기존의 학습률로도 loss가 잘 감소하고 있었는데, learning rate decay를 적용하여 되려 학습이 잘 이루어지지 않고 있습니다. 이는 learning rate decay를 너무 일찍 적용하여 발생한 문제입니다.
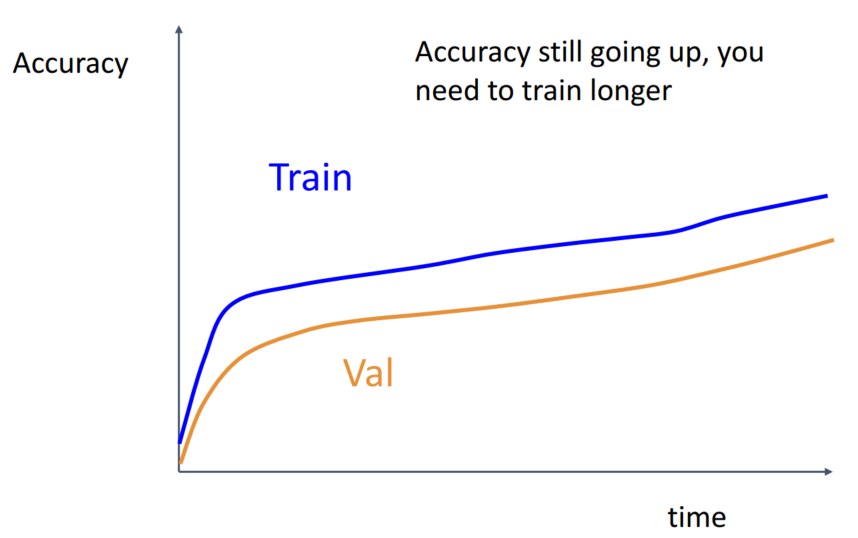
Accuracy가 Train, Validatino 모두에서 잘 증가하고 있습니다. 학습을 더 진행해도 괜찮음을 의미합니다.
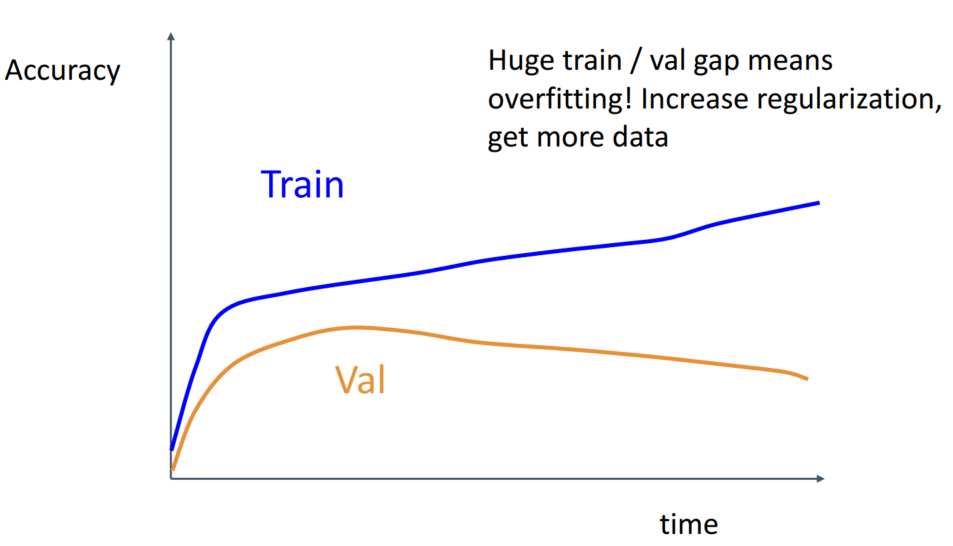
Train에서는 성능이 좋지만, Validation에서는 성능이 낮은 것은 overfitting 되었음을 의미합니다. overfitting을 해결하기 위해 regularization을 늘리거나 data를 늘려줍니다.
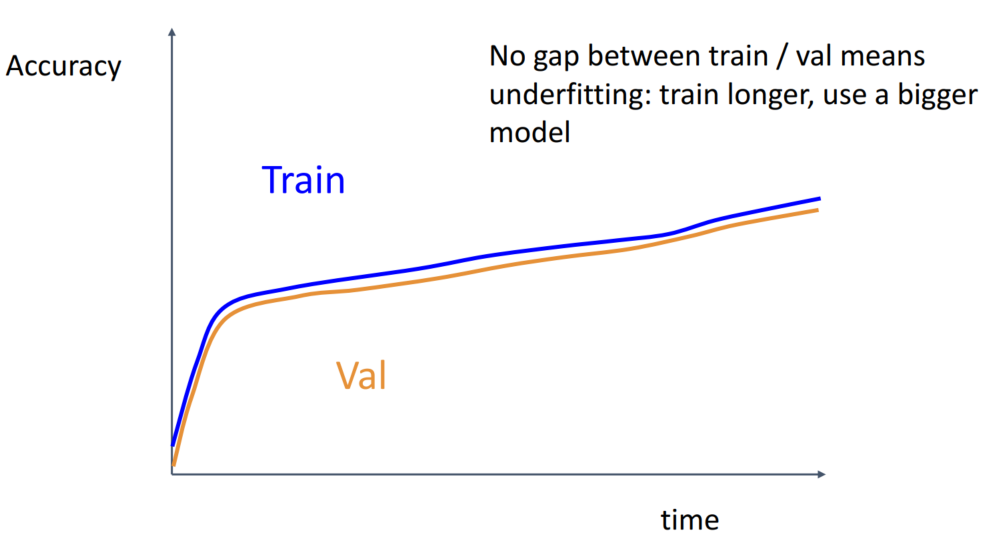
Gap도 없고, Train, Validaion 모두 증가하는 모습으로 짐작하여 잘 학습되고 있다고 생각할 수 있습니다. 하지만 이는 underfitting이 되었음을 의미하기에 학습을 더 시키거나 더 큰 모델을 사용해야 합니다.
Model Ensembles
Model Ensembles은 다수의 독립적인 모델을 학습한 후에, test time에서 그 결과들을 평균 내어 argmax를 사용하는 방법입니다. 큰 성능 향상을 기대한다기보다는, 2% 정도의 성능 향상을 위해 사용합니다.
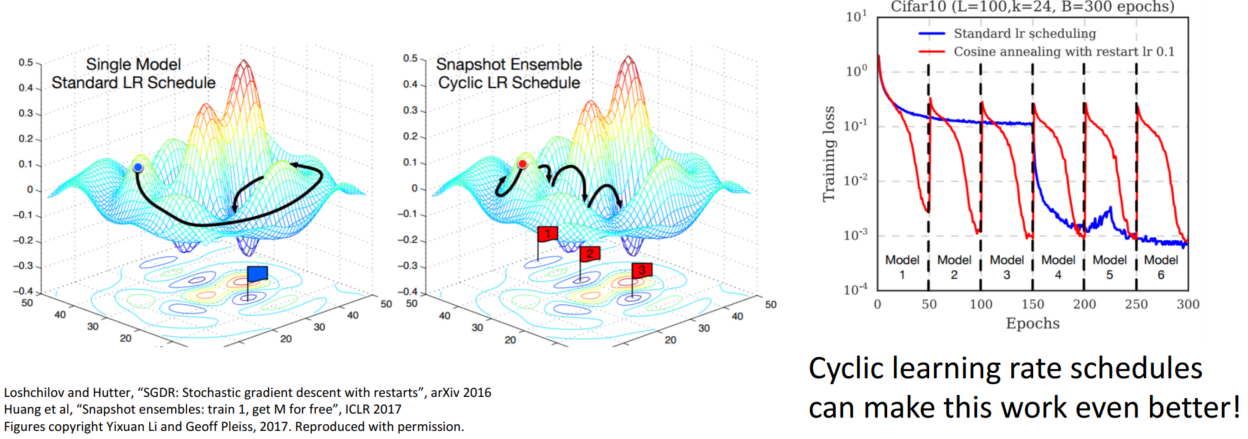
Tips and Tricks은 독립적인 모델을 사용하는 것이 아니라 learning rate schedule을 사용하여 학습률을 decay → up →decay... 를 통해 구간별 모델 평균을 활용하는 방법입니다.
Transfer Learning
CNN과 같은 큰 모델을 학습하기 위해서는 많은 데이터가 필요했고, 이는 정설로 받아들여졌습니다. 하지만 Transfer Learning(전이학습)은 적은 데이터로도 모델 학습이 가능함을 보여주었습니다.

전이 학습은 다른 데이터셋으로 학습된 모델에서 맨 마지막 layer만 제거한 후, 학습시키고자 하는 데이터셋에서 학습을 통해 사용하는 방법입니다. 주로 Imagenet 데이터를 학습한 모델을 사용합니다. 전이학습을 통해 한 카테고리당 100개 이하의 이미지를 지닌 데이터셋도 학습가능합니다. 우측의 그래프를 보면, 해당 데이터셋의 SOTA를 전이학습한 모델이 가볍게 능가함을 확인할 수 있습니다.
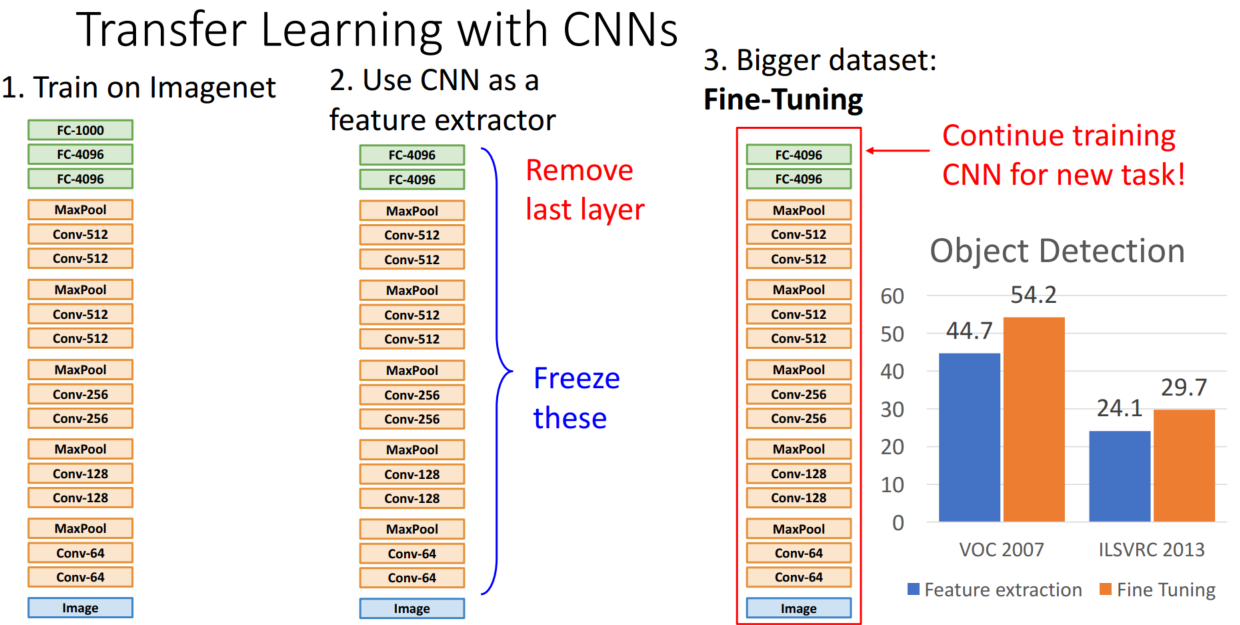
데이터가 조금 더 많아진다면, 모델을 그대로 활용하는 것이 아니라 모델을 추가적으로 학습시키는 Fine-Tuning을 진행할 수 있습니다. 우측의 그래프를 보시면 단순히 모델을 활용하는 것보다, Fine-Tuning을 진행할 때 성능이 향상되는 것을 확인할 수 있습니다.
Some Tricks
- Train with feature extraction first before fine-tuning
- Lower the learning rate: use ~1/10 of LR used in original training
- Sometimes freeze lower layers to save computation
*Transfer learning = pre-training + fine-tuning
*전이학습이 잘 작동하는 이유는 낮은 layer는 일반적인 특징, 높은 layer는 고유한 특징을 추출하기에 CNN에서 학습한 일반적인 특징은 다른 이미지에서도 사용 가능한 것 같음. CNN의 Filter는 윤곽, 채도 등 여러 특징들을 각각 학습하니 이는 다른 이미지에서도 적용 가능함
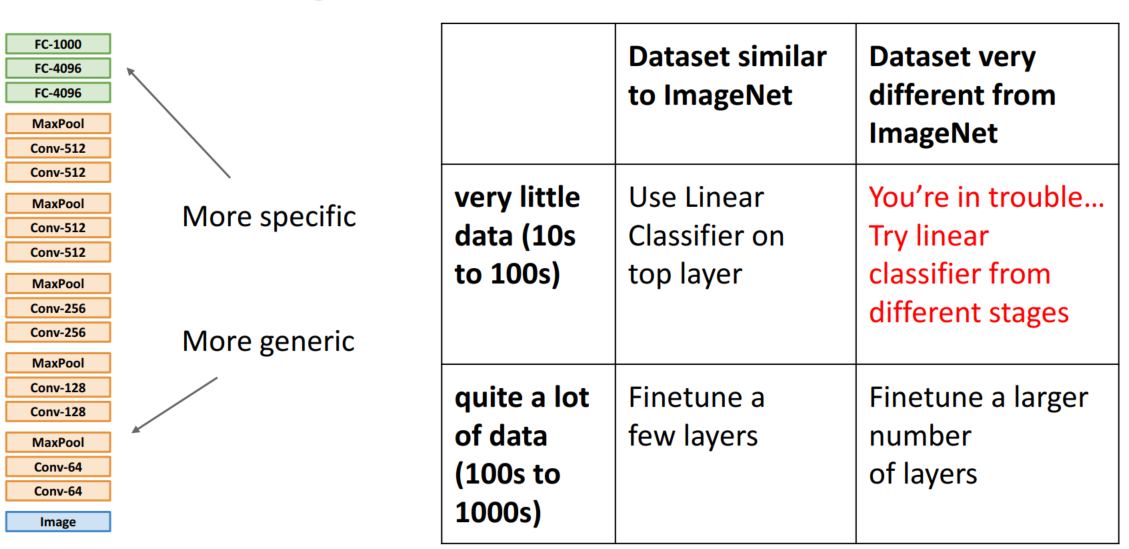
데이터의 종류와 크기에 따른 전이학습 방법을 살펴보겠습니다.
- Case 1. Imagenet과 데이터셋이 유사 & 적은 데이터의 양: Top layer에서 선형 분류기를 사용합니다.
- Case 2. Imagenet과 데이터셋이 유사 & 많은 데이터의 양: Fine-Tuning 진행
- Case 3. Imagenet과 데이터셋이 유사하지 않음 & 많은 데이터의 양: 더 많은 layer를 Fine-Tuning
- Case 4. Imagenet과 데이터셋이 유사하지 않음 & 적은 데이터의 양: You are in trouble...
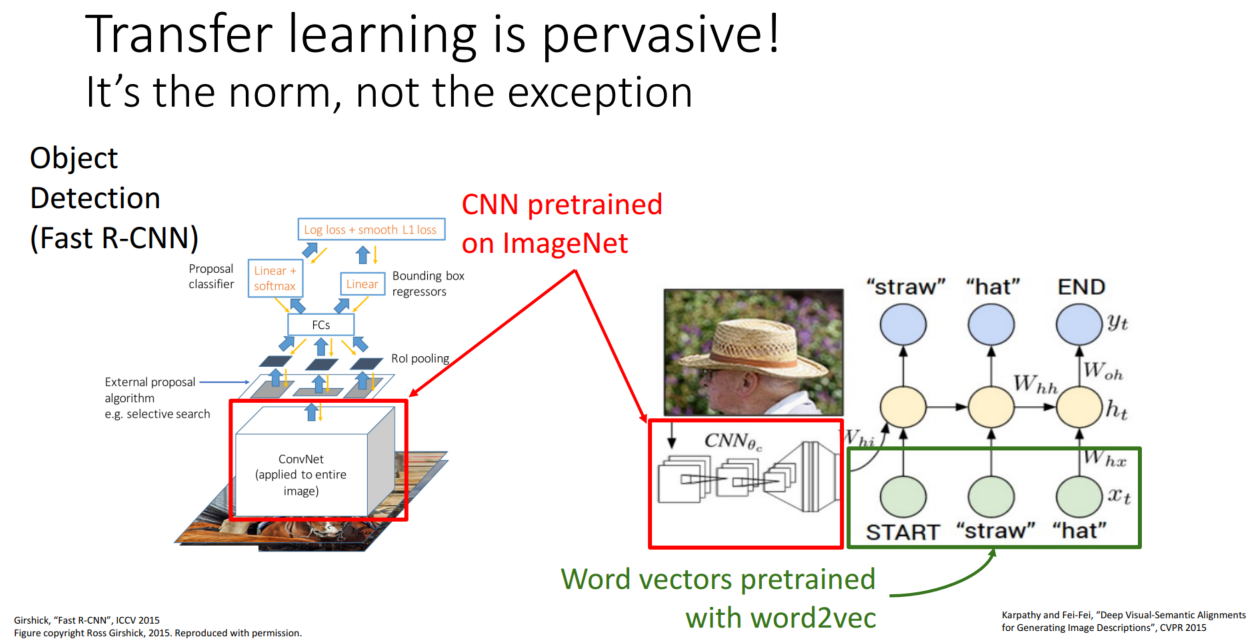
pretrained 된 모델 여러 개를 합쳐 새로운 모델을 만들 수도 있습니다.
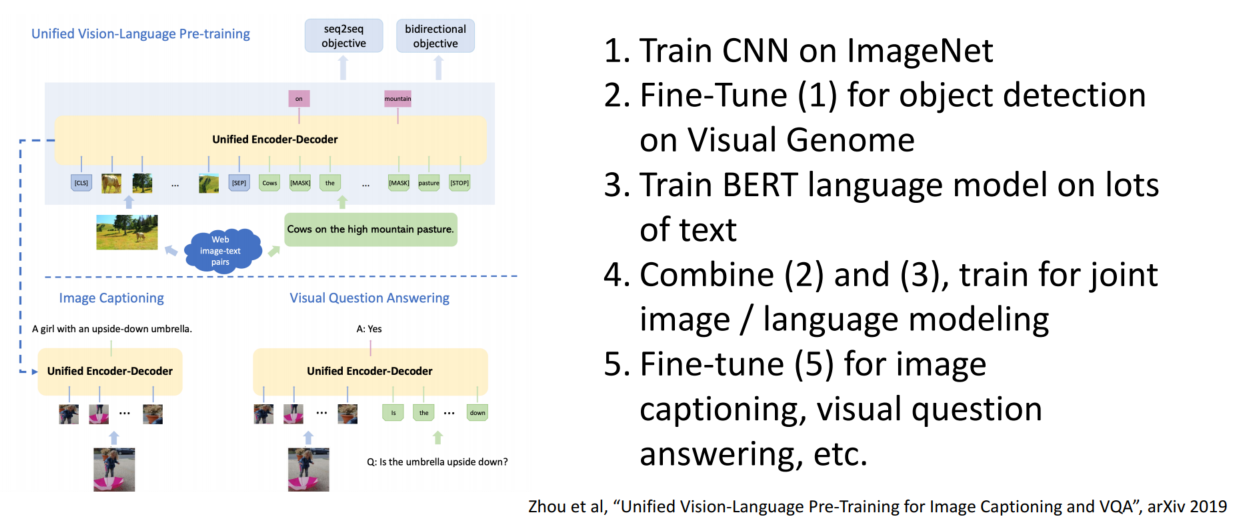
전이학습이 필요하지 않을 정도의 데이터를 가지고 있더라도 전이학습을 사용하면 빠른 학습이 가능합니다.
Distributed Training
큰 모델을 학습할 때는 시간이 매우 많이 걸리는 문제가 있습니다. Distributed Training(분산 학습)은 학습 시간을 줄에는 데 필수적인 기술입니다.
Model Parallelism
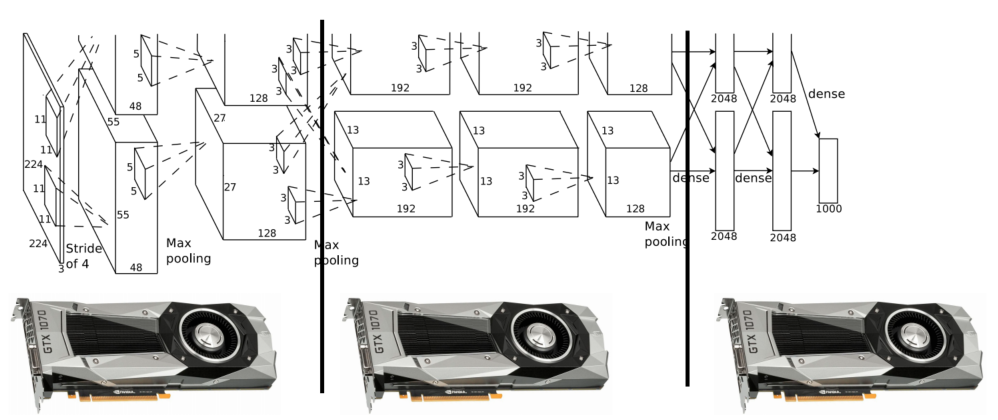
첫 번째 아이디어는 GPU별로 다른 layer를 학습하도록 하는 것입니다. 이 아이디어를 사용하면 자신의 역할이 끝난 GPU는 기다리는데 많은 시간을 소모하고, 이는 GPU 1개를 사용하는 효과와 동일합니다.
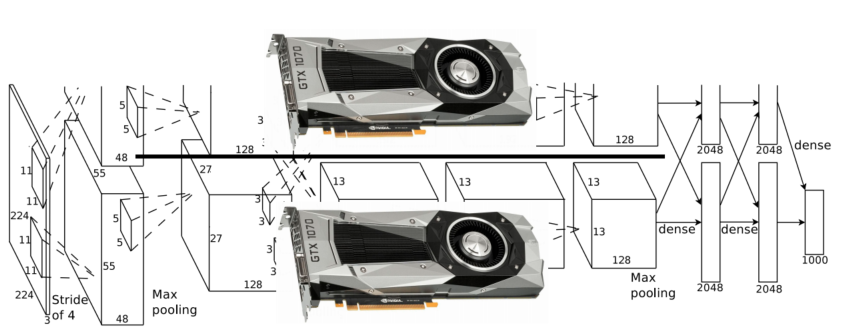
두 번째 아이디어는 GPU별로 평행한 모델을 학습하는 것입니다. 이때 모델을 평행하게 분리합니다. 하지만 이 방법은 GPU 간 동기화를 하는데 많은 비용이 들고 activation과 grad activation을 해야 합니다.
Data Parallelism
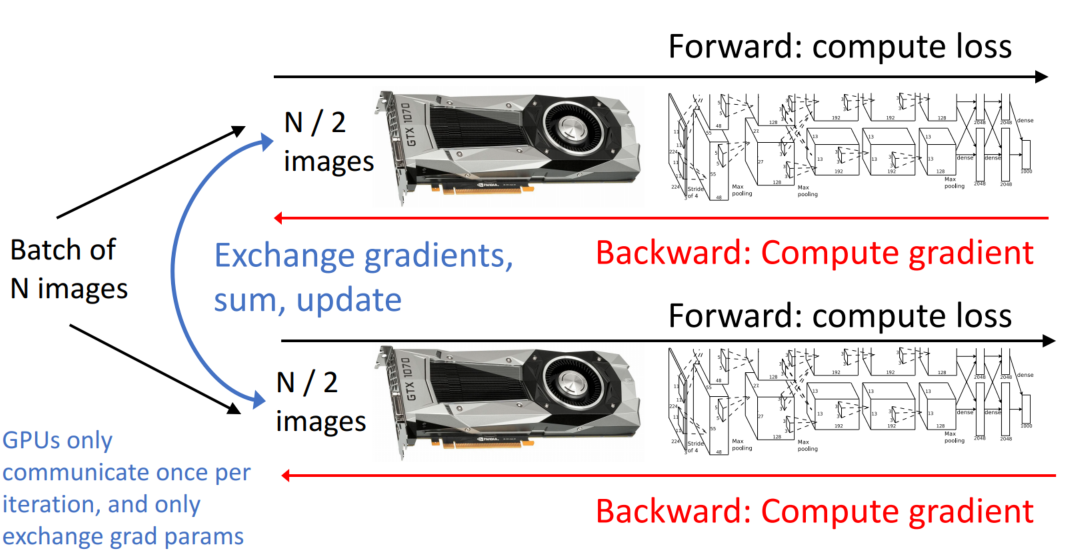
세 번째 아이디어는 각 GPU별로 같은 모델을 학습하는 것입니다. 이때 데이터를 분리합니다. GPU는 iteration별로 한 번만 소통하고, grad parameter를 교환합니다.
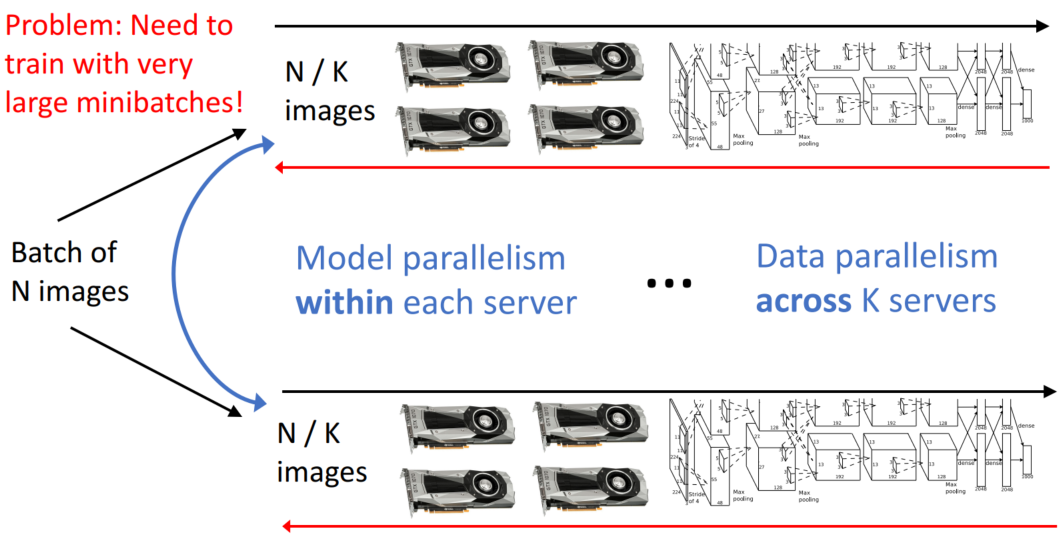
일반화하면 다음과 같습니다.
분산학습은 강의에서 깊게 다루지 않기에 블로그 링크를 공유합니다.
https://wooono.tistory.com/331
[DL] Distributed Training (분산 학습) 이란?
Distributed Training (분산 학습) 이란? 딥러닝 모델 설계 과정에는 많은 시간이 소요됩니다. 따라서, 모델의 학습 과정을 가속화하는 것은 매우 중요합니다. 분산 학습은 이러한 딥러닝 모델의 학습
wooono.tistory.com
'공부 정리 > Machine learning & Deep learning' 카테고리의 다른 글
| [EECS 498-007 / 598-005] Lecture 13: Attention (0) | 2023.02.09 |
|---|---|
| [EECS 498-007 / 598-005] Lecture 12: Recurrent Neural Networks (0) | 2023.02.08 |
| [EECS 498-007 / 598-005] Lecture 8: CNN Architectures (0) | 2023.01.26 |
| [EECS 498-007 / 598-005] Lecture 7: Convolutional Networks (0) | 2023.01.24 |
| [EECS 498-007 / 598-005] Lecture 6: Backpropagation (0) | 2023.01.17 |



