- 본 게시글은 Justin Johnson 교수님의 Deep Learning for Computer Vision, University of Michigan 정리글입니다.
- 개인적인 생각이 서술되어 있습니다. 잘못된 내용이 존재할 확률이 존재하기에 주의 바랍니다.
- 잘못된 내용, 오타는 지적해 주시면 감사하겠습니다.
강의링크:
https://www.youtube.com/watch?v=XaZIlVrIO-Q&list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r&index=8
강의자료:
https://web.eecs.umich.edu/~justincj/slides/eecs498/498_FA2019_lecture08.pdf
ImageNet
ImageNet은 1,000개의 카테고리로 구성된 100만 개가 넘는 대규모 Image set입니다. ILSCRC는 ImageNet 데이터를 분류하는 대회입니다. 2012년 CNN 기반 딥러닝 알고리즘인 AlexNet을 기점으로 Accuracy가 확연히 높아졌던 대회로, 여러 유명한 모델들이 나온 대회입니다.
AlexNet (2012)

- 227 x 227 inputs
- 5 Convolutional layers
- Max pooling
- 3 fully-connected layers
- ReLU nonlinearities
- Trained on two GTX 580 GPUs (3GB of memory each)
AlexNet의 연산을 진행해보겠습니다. 먼저 첫 번째 Convolution layer입니다.
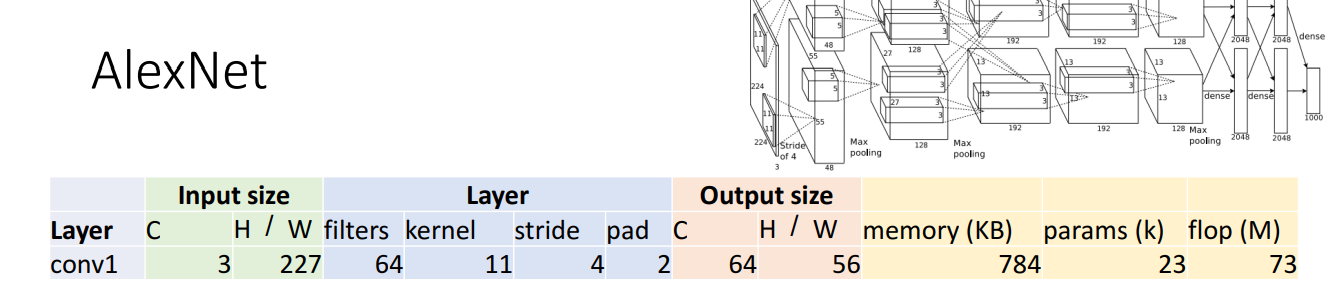
Input size와 Layer는 주어진 값 및 설정한 값입니다. 이를 바탕으로 Ouput size를 알아보겠습니다.
- Output channels = # of filters = # of activation map → 64
- Output H / W = (W-K+2P) / S + 1 = (227-11+2x2) / 4 + 1 → 56
- memory(KB) = (number of elements) x (bytes per elem) / 1024 = (CxH'xW') x 4 / 1024 = 64x56x56x4 / 1024 = 784
- params(k) = Weight shape + Bias shape = 64x3x11x11 + 64 = 23,296
- flop(M) = (number of output elements) * (ops per output elem) = (C_out x H’ x W’) * (C_in x K x K) = (64 * 56 * 56) * (3 * 11 * 11) = 72,855,552
*float type: 4byte (32bit)의 공간에 실수를 저장
*FLOPS(Floating point Operation Per Second): 단위 시간당 얼마나 많은 연산을 하는지를 보여주는 지표. 딥러닝에서는 절대적인 연산량의 횟수를 일컬음
다음은 Pooling layer입니다. 참고로 Convolution layer와 Pooling layer사이에 ReLU가 적용되었습니다.

Pooling layer의 Input은 Convolution을 거치고 만들어진 Activation map이므로 Input은 Convolution의 Output과 동일합니다.
- # of output channels = # of input channels → 64
- Output H / W = (W-K+2P) / S + 1 = (56-3+0) / 2 + 1 → floor(27.5) → 27
- memory(KB) = 64 x 27 x 27 x 4 / 1024 = 182.25
- params(k) → Pooling layers have no learnable parameters!
- flop(M) = 0.4MFLOP인데, pooling에서의 flop은 Convolution layer와 비교하면, 현저히 작으므로 포함하지 않습니다.
AlexNet의 최종적인 형태는 다음과 같습니다.

보기에도 복잡한 AlexNet의 구조는 어떻게 만들어졌을까요? Trial and error 방식으로 실험을 거쳐 좋은 성능을 보이는 모델을 찾았다고 말합니다.
아래의 그래프에서 AlexNet, Convolution layer, Fully connected layer의 특징을 확인할 수 있습니다.

- Memory usage는 대부분 early Convolution에서 발생합니다.
- Parameters는 대부분 Fully conncted에서 만들어지고, Fully connected에서 학습됩니다. 이는 flattening을 거친 후, Input이 엄청나게 늘어남에서 기인합니다. Parameter가 가장 많은 fc6을 연산해보면 weight shape = 9216 x 4096 = 37,749(k)가 됩니다. / Ignoring bias
- 반면 MFLOP은 내적을 비롯한 연산이 많이 발생하는 Convolution에서 대부분 차지합니다.
ZFNet (2013)
AlexNet이 획기적인 성능을 발휘한 다음해인, 2013년에는 ZFNet이 ImageNet에서 우승을 차지했습니다. ZFNet은 Bigger AlexNet이라 불리는 것처럼, 새로운 혁신을 만들었다기보다는 더 많은 trial and error로 성능을 끌어올린 모델입니다.

- CONV1: AlexNet (11x11 stride 4) → ZFNet (7x7 stride 2)
- CONV3,4,5: AlexNet (384, 384, 256 filters) → ZFNet (512, 1024, 512)
일반적으로 더 많은 계산을 수행하는 모델이 더 좋은 성능을 발휘합니다. ZFNet은 stride를 줄이고, filter의 수를 늘림으로써 더 많은 계산을 수행하였습니다.
- stride↓→ Down sampling↓ → 더 많은 계산
- # of Filter↑ → 더 많은 계산
VGG (2014)
VGG는 ZFNet과 다르게 새로운 패러다임을 제공했습니다. Hyperparameter를 실험적으로 변경하며 좋은 성능을 찾는 것이 아니라, 규칙을 제공했습니다. 참고로 VGG 16, 19는 Layer의 수가 16개, 19개임을 의미합니다.

VGG는 5 Stage로 구성됩니다. Stage들이 유사함이 보이시나요?
Stage 1: conv-conv-pool
Stage 2: conv-conv-pool
Stage 3: conv-conv-pool
Stage 4: conv-conv-conv-[conv]-pool
Stage 5: conv-conv-conv-[conv]-pool
1. All conv are 3x3 stride 1, pad 1

Option 1과 Option 2는 same receptive field size를 가집니다. 하지만 Option 2를 사용하면 3가지 효과가 있습니다. + Convolution size를 어떻게 설정할지 고민하지 않고(하이퍼파라미터 고려 x), 몇 층을 만들것인가만 고민하면 됩니다.
- Parameters 수가 작음
- FLOPs가 작음
- Conv-Conv 사이에 ReLU를 거치기에 더 깊어지고, nonlinear computation 효과를 가질 수 있음
그럼 왜 Option 2에서 Parameters가 줄어들까요? 첫번째 Conv는 9C**2의 연산이, 두번째 Conv에서도 9C**2의 연산이 요구되기에 (9C**2 + 9C**2 = 18C**2)가 됩니다.
2. All max pool are 2x2 stride 2 / After pool, double #channels

좌측은 Max polling 전, 우측은 Max pooling 후입니다. Max pooling을 통해 parameter는 늘어났지만 FLOPs는 동일하고, Memory는 절반으로 줄어들었습니다. 즉 더 좋은 성능을 발휘합니다.
아래의 그래프는 AlexNet과 VGG-16을 비교한 그래프입니다. VGG-16의 네트워크가 엄청나게 커진 것을 확인 가능합니다.

GoogLeNet (2014)
2014년은 VGG, GoogLeNet이라는 획기적인 모델이 제안된 해이며, 우승은 GoogLeNet이 차지하였습니다. 이전까지의 모델은 bigger network perform better는 기조 아래 만들어졌는데, 구글은 efficiency에 초점을 맞추었습니다.(구글은 실제로 사용할 목적으로 개발함으로)
* Many innovations for efficiency: reduce parameter count, memory usage, and computation
1. Aggressive Stem

AlexNet과 VGG에서 Convolution에서 많은 Memory 사용과 MFLOP가 발생함을 확인하였습니다. GoogLeNet은 efficiency에 초점을 맞추었으므로, 처음부터 downsampling을 빠르게 진행하였습니다. VGG와 비교했을 때 확연히 줄어든 숫자를 확인 가능합니다.
2. Inception Module

VGG에서는 3x3 Convolution을 반복하여 만들었습니다. 반면 GoogLeNet은 1x1, 3x3, 5x5 등 여러 kernel size를 모두 사용하였습니다. 또한 1x1 convolution으로 Channel의 차원을 줄인다음, convolution을 수행하여 비용을 절약합니다.
3. Global Average Pooling

VGG-16까지는 Fully-connected 이전에 flattening을 진행하였습니다. 이는 차원의 특징을 분산시켜주는 장점이 있지만, 파라미터 수가 늘어난다는 단점도 있습니다. GoogLeNet에서는 Flattening대신 마지막 convolution size와 동일한 average pooling을 사용하여, 이 문제를 해결합니다.
4. Auxiliary Classifiers

GoogLeNet (2014)은 Batch Normalization (2015) 이전에 개발되었습니다. Batch Normalization 이전에는 10개 이상의 layer를 쌓기도 힘든 문제가 있었기에 GoogLeNet은 Auxiliary Classifiers로 이를 해결하였습니다.
Residual Networks (2015)
Batch Normalization이 개발된 이후, 10개 이상의 layer로 네트워크 구성이 가능해졌습니다. 하지만 Deeper model이 Shallow model보다 좋지 않은 성능을 발휘하였습니다.

Deep model이 overfitting 되었을 것이라고 추측하였지만, Training set에서도 Deep model이 Shallow model보다 좋지 않은 성능을 보였음을 통해 사실은 underfitting되어있음을 확인하였습니다.
Deeper model은 Shallower model을 모방하여 만든 후, layer를 추가한 것이기에 최소한 Shallow model의 성능을 보여야합니다. 따라서 다음과 같은 가정과 해결책을 떠올렸습니다.
가정: 최적화가 문제입니다. Deeper model은 최적화하기 힘들고, 특히 shallow model을 모방하기 위한 identity function 학습이 잘 이루어지지 않습니다.
해결책: Extra layer에서 identity functions의 학습이 쉽도록 network를 바꾸자!

좌측은 VGG의 Convolution layer입니다. 우측은 Residual block으로, F(x)에 x를 더하여 결과를 산출합니다. Convolution layer의 weight=0으로 설정하면, 전체 block은 x와 같은 효과를 발휘하여 identity function를 쉽게 학습할 수 있게되었습니다.
Residual Networks는 Residual Block들이 쌓여있는 Network입니다.

Residual Networks는 GoogLeNet처럼 시작 부분에는 aggressive stem으로 downsampling을 진행하고, 끝 부분에서는 global average pooling을 수행합니다.
ResNet 또한 ResNet-18, ResNet-34 처럼 다양한 종류가 있습니다. 18, 34는 layer의 수를 의미합니다.

ResNet-18은 Basic Residual Block을 사용하는 반면, ResNet-34는 Bottleneck Block을 사용합니다.

Bottleneck Residual Block은 첫번째 Convolution Channel 수를 1/4로 줄인 후 → 3x3 Convolution → Convolution Channel 수를 4배 (처음처럼)합니다. Total FLOPs의 효과가 엄청 크지는 않지만 non linearity, more complex types of computation이 추가되는 효과가 있습니다.

서로 다른 대회에서 여러 모델이 수상하던 경향과 달리, ResNet은 모든 대회를 휩쓸었습니다.

Block의 순서 변경을 통해, 약간의 성능 향상도 가능합니다.

Compare Model

좌측의 그림은 정확도, 우측의 그림은 계산량을 보여줍니다. 좌측의 막대바가 클수록, 우측의 원이 작을수록 좋음을 의미합니다.
- AlexNet: Low compute, lots of parameters
- VGG: Highest memory, most operations
- GoogLeNet: Very efficient!
- ResNet: Simple design, moderate efficiency, high accuracy
ImageNet 대회는 2017년까지 진행되었고, 각 모델의 정확도와 layer를 보여주는 그래프입니다.

ResNeXt
Bottleneck Residual Block을 평행하는 G개만큼 사용하는 것입니다.



'공부 정리 > Machine learning & Deep learning' 카테고리의 다른 글
| [EECS 498-007 / 598-005] Lecture 12: Recurrent Neural Networks (0) | 2023.02.08 |
|---|---|
| [EECS 498-007 / 598-005] Lecture 11: Training Neural Network (0) | 2023.02.01 |
| [EECS 498-007 / 598-005] Lecture 7: Convolutional Networks (0) | 2023.01.24 |
| [EECS 498-007 / 598-005] Lecture 6: Backpropagation (0) | 2023.01.17 |
| [EECS 498-007 / 598-005] Lecture 5: Neural Network (2) | 2023.01.11 |



