- 본 게시글은 Justin Johnson 교수님의 Deep Learning for Computer Vision, University of Michigan 정리글입니다.
- 개인적인 생각이 서술되어 있습니다. 잘못된 내용이 존재할 확률이 존재하기에 주의 바랍니다.
- 잘못된 내용, 오타는 지적해 주시면 감사하겠습니다.
강의링크:
https://www.youtube.com/watch?v=dUzLD91Sj-o&list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r&index=12
강의자료:
https://web.eecs.umich.edu/~justincj/slides/eecs498/498_FA2019_lecture12.pdf
RNN Process Sequences

one to one
- ex) Image classification, Image → Label
- 기본 구조
one to many
- ex) Image Captioning, Image → sequence of words
- 사진에 설명을 붙일 때 사용
many to one
- ex) Video classification, Sequence of images → label
- 여러 장면으로 구성된 비디오 분류, 감성 분석
many to many
- ex) Machine Translation, Sequence of words → Sequence of words
- ex) Per-frame video classification, Sequence of images → Sequence of labels
RNN은 Non-Sequential data에도 적용가능합니다.
Feedforward방식으로 진행되었던 이미지 분류 문제를, glimpses들의 series로 보고 분류하는 문제로 변형가능합니다.
hidden state에는 현재시점의 input과 이전시점의 hidden state가 입력되어 가중치와 행렬곱을 진행합니다. 다음으로 tanh 활성화 함수를 통과하여 hidden state를 완성합니다. 완성된 hidden state와 가중치가 곱해져 현재시점의 output을 도출하게 됩니다.
RNN Computational Graph
Mnay to One은 위와 같고,
One to Many는 위와 같습니다.
Sequence to Sequence (seq2 seq)는 기계 번역에서 주로 사용되는 모델입니다. 영어 → 프랑스어 번역을 한다고 했을 때, 영어와 프랑스어는 항상 일대일 대응이 이루어지지 않습니다. 문장의 길이가 다른 단어들의 sequence로 이루어질 수 있으므로, 두 개의 모델을 합쳤습니다.
크게 다음의 2단계로 구성됩니다.
1. Many to One에서는 영어 단어를 입력으로 받아서 h_T로 내보내는 Encoding을 진행합니다.
2. One to many에서는 h_T를 W_2와 함께 프랑스어로 Deconding을 진행합니다.
그럼 Language Modeling 예시를 통해 RNN을 자세히 살펴보겠습니다.
'hello'는 단어를 학습한다고 하면 input으로는 h, e, l, l이 순차적으로 들어가고, 이에 대응하여 e, l, l, o가 순차적으로 target이 됩니다.

각 input chars는 one-hot-encoding을 통해 vector로 변환합니다. 이때 중복을 제외한 hello의 글자는 4개(h, e, l , o)이므로 4x1 vector로 변환됩니다.
* [1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]
e를 예측하는 과정은, 먼저 input, h_0이 입력되면 h_1이 계산됩니다. 이를 바탕으로 cross entroy를 통해, e가 나오도록 학습합니다. cross entropy 값을 보시면 학습 초기에는 아직 부족함을 확인하실 수 있습니다.
*h_0: 첫 번째 hidden state를 계산할 때는, 참고할 이전 hidden state가 없기에 random 값을 사용합니다

마찬가지로 I를 예측할 때는, <h, e>를 활용하여 hidden state를 계산하여 예측합니다. 그다음 I를 예측할 때는 h, e, l를 모두 활용하여 hidden state를 계산합니다.
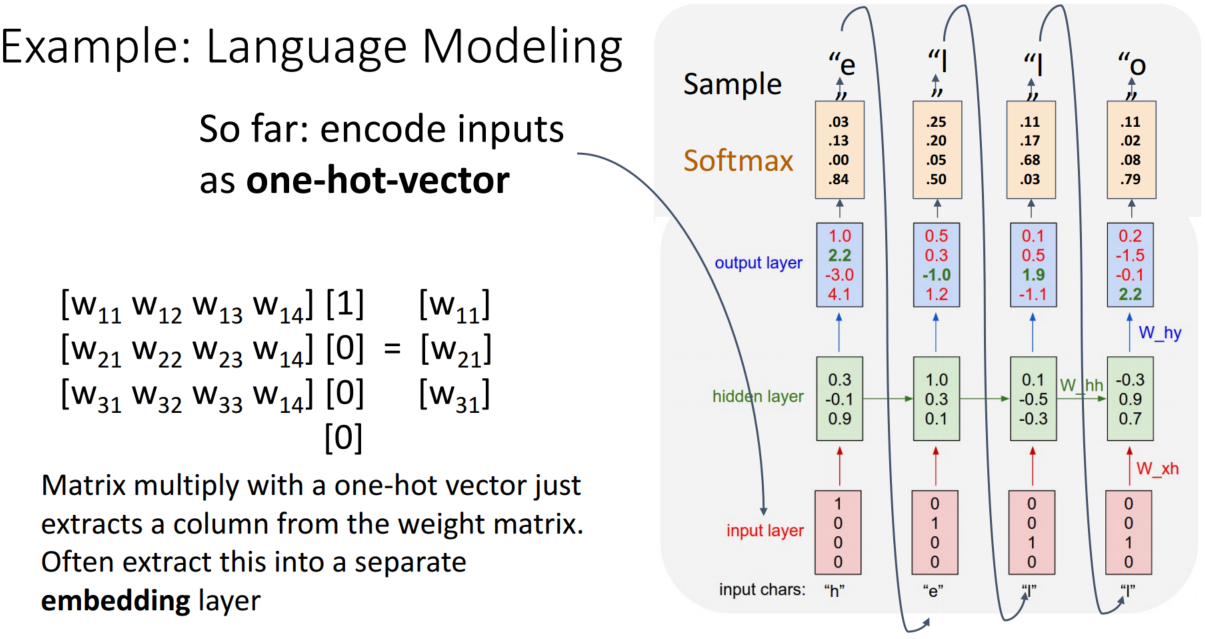
앞서 살펴본 내용은 학습과정이고, 지금부터 살펴볼 test-time에서는 h만 입력하고 hello가 잘 나오는지 보는 식으로 진행됩니다. hidden state는 weight matrix와 one-hot-encoding을 한 vector를 곱하여 계산합니다. 여기서 자세히 살펴보면, one-hot-encoding을 진행하였기에 하나의 인자는 1, 나머지는 모두 0입니다. 이를 weight matrix에 곱하면 하나의 column을 추출하는 것과 같습니다.
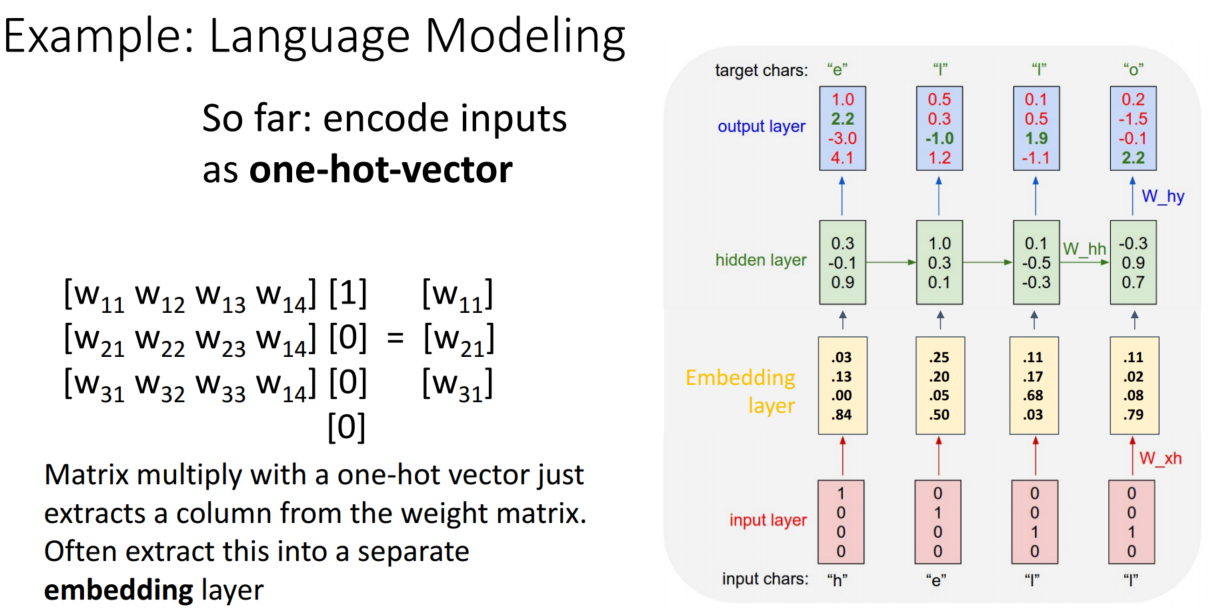
Truncated Backpropagation Through Time

Sequence가 길어질수록 forward로 loss를 계산 & backward로 gradient를 계산하는 과정을 진행하는 데는 두 가지 문제가 있습니다.
1. 너무 많은 계산량과 메모리 소모
2. 계층이 길어지면 gradient가 조금씩 작아져 기울기 소실 문제가 있음
이 문제를 해결하기 위해 Truncated Backpropagation을 사용합니다.

전체 Sequence에 대해 forward와 backward를 진행했던 이전과 다르게, Truncated Backpropagation은 Sequence를 chunk 단위로 나눈 후 chunk별로 forward와 backward를 진행합니다. 이때 조심해야 할 것은 backward만 chunk 단위로 나누는 것입니다. 만약 forward도 나누게 된다면, 흐름이 전달되지 않겠지요?
Image Captioning

이미지를 CNN을 통해 정보가 요약된 vector를 출력하고, 출력된 vector를 RNN에 넣어 Image Captioning을 진행합니다. 단순히 cat / dog를 분류하는 것은 CNN 단계만으로도 가능하지만, Image 설명을 하기 위해서는 RNN까지 거쳐야 합니다.

Imagenet으로 학습한 CNN 모델은 전이 학습(Transfer learning)을 통해 사용합니다. 전이 학습에서는 마지막 layer 2개(FC-1000, softmax)를 제외하고 사용하였습니다.

RNN 모델만 사용할 때는 현재 input & 이전 hidden state로 현재 hidden state를 계산하였습니다. 그러나 CNN과 함께 사용할 때는 이미지 정보도 추가해야 합니다. W_ih x v가 추가되었습니다. RNN은 <START> token으로 시작하여 <END> token으로 끝납니다.

상황을 잘 묘사해 주는 것을 확인할 수 있습니다.

물론 실패 사례도 많이 존재합니다. 학습할 때 어떤 이미지를 위주로 학습하였느냐에 따라 많이 달라지는 것을 확인할 수 있습니다. 지도 학습이기에, 라벨링을 잘못해도 그럴 수 있습니다.
강의를 보면서 떠오른 게 있었는데요, 바로 OpenAI의 DALL-E 2입니다. DALL-E 2는 그림을 그려주는 인공지능으로, 영어 텍스트를 입력하면 상황에 맞는 그림을 생성해 줍니다. 특정 작가의 화풍으로 그려달라고 하면, 그에 맞는 그림을 생성할 정도로 정교합니다.
'살바도르 달리 스타일의, 세계를 여행하는 자유로운 영혼'을 그려달라고 입력한 결과입니다.

DALL-E 2에 사용된 알고리즘을 확인하진 못하였지만, 아마 우리가 공부한 모델들을 바탕으로 구축되지 않았을까 조심히 추측해 봅니다.
Vanilla RNN Gradient Flow

RNN의 hidden state h_t는 x_t (현재 input)와 h_(t-1) (이전 hidden state)에 가중치를 행렬곱한 후, tanh 연산을 수행하여 만듭니다. forward pass는 이런 식으로 진행됩니다.
그럼 backward pass는 어떻게 진행될까요?

backward pass에서는 두 가지 문제가 발생합니다.
1. Exploding gradients: Largest singular value > 1
2. Vanishing gradients: Largest singular value < 1
backward pass에서 사용되는 gradient는 tanh, +, x입니다. +는 gradient를 전달만 하고 변하지 않습니다. 하지만 tanh, x는 그렇지 않습니다.
tanh을 미분해 보면 0 ~ 1의 범위를 가지고, x가 크거나 작으면 점점 0에 수렴합니다. 최댓값이 1이니, gradient는 시간이 지나면서 점점 작아져 vanishing gradients 문제를 만들 수 있습니다.
x는 반복 횟수에 따라 똑같은 (w_h)**T가 곱해집니다. 예를 들어 처음엔 (w_h)**T, 두 번째에는 (w_h)**Tx(w_h)**T 이런 식으로 말이죠. 여기서 (w_h)**T가 1보다 작은지 큰지에 따라, gradient는 시간이 지나면서 점점 작아지거나 커져 vanishing gradients, exploding gradients 문제를 만들 수 있습니다. RNN의 문제를 해결하기 위해 LSTM(Long Short Term Memory)이 제안되었습니다.
*문제를 만들 가능성이 있다는 것이지, 항상 그렇다는 것은 아닙니다
LSTM
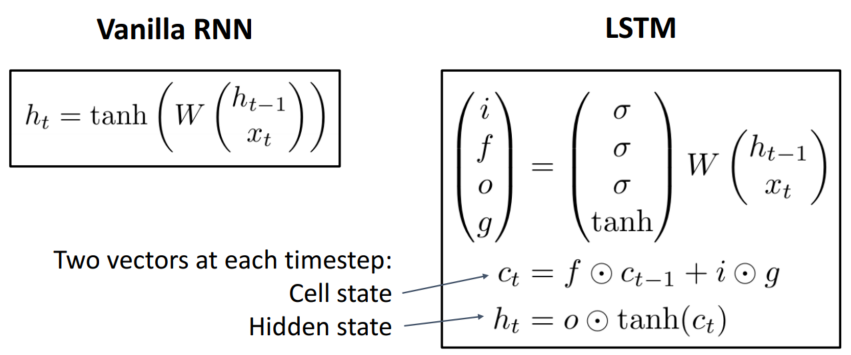
LSTM은 RNN의 hidden state에 cell state를 추가한 구조입니다. 바로 이전의 hidden state만 참고하는 RNN과 달리, cell state를 추가한 LSTM은 오랜 시점 이전에 나온 state들도 상대적으로 잘 기억합니다.

i: Input gate
- whether to write to cell, 활성화 함수로 sigmoid(출력 범위: 0 ~ 1) 사용
f: Forget gate
- Whether to erase cell, 활성화 함수로 sigmoid(출력 범위: 0 ~ 1) 사용
o: Output gate
- How much to reveal cell, 활성화 함수로 sigmoid(출력 범위: 0 ~ 1) 사용
g: Gate gate
- How much to write to cell, 활성화 함수로 tanh(출력 범위: -1 ~ 1) 사용
*tanh 함수는 정보의 정도를, sigmoid 함수는 데이터를 얼마큼 사용할지를 정하는 역할을 담당
아래의 수식을 잠시 살펴보겠습니다. cell state의 첫 번째 항은 과거 정보를 얼마나 잊을지, 두 번째 항은 현재 정보를 얼마나 사용할지를 의미합니다. 이렇게 계산된 cell state가 연산을 통해 hidden state로 계산됨을 확인 가능합니다. 즉, 기존의 hidden state를 계산하는 방법에서 얼만큼 과거 정보를 사용할지를 추가한 느낌입니다.

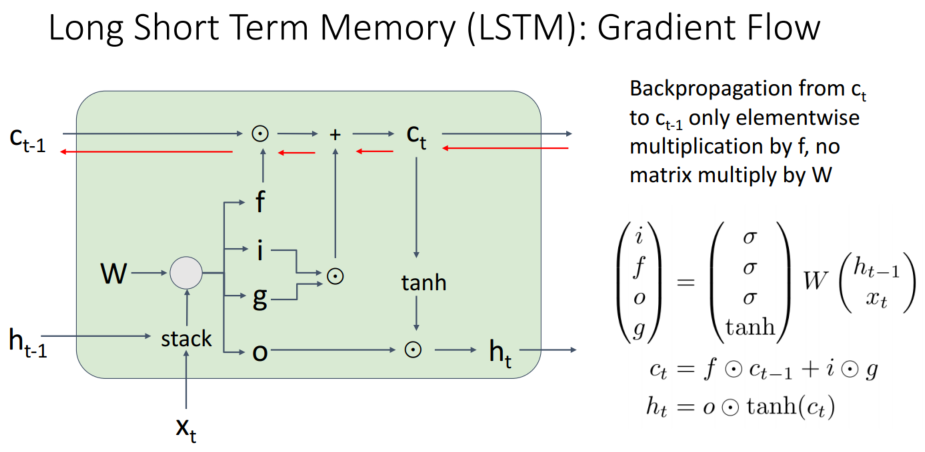
backward pass에서 사용되는 gradient는 +, x입니다. +는 gradient 전달만 담당하기에 gradient가 변하지 않습니다. x는 RNN과 다르게 행렬곱이 아닌 아다마르 곱을 계산합니다. 아다마르 곱은 매번 새로운 값을 이용하여, 곱셈 값이 누적되지 않습니다. 따라서 gradient vanishing이 일어나기 어렵습니다.

'공부 정리 > Machine learning & Deep learning' 카테고리의 다른 글
| [EECS 498-007 / 598-005] Lecture 19: Generative Models I (0) | 2023.02.15 |
|---|---|
| [EECS 498-007 / 598-005] Lecture 13: Attention (0) | 2023.02.09 |
| [EECS 498-007 / 598-005] Lecture 11: Training Neural Network (0) | 2023.02.01 |
| [EECS 498-007 / 598-005] Lecture 8: CNN Architectures (0) | 2023.01.26 |
| [EECS 498-007 / 598-005] Lecture 7: Convolutional Networks (0) | 2023.01.24 |



