- 본 게시글은 Justin Johnson 교수님의 Deep Learning for Computer Vision, University of Michigan 정리글입니다.
- 개인적인 생각이 서술되어 있습니다. 잘못된 내용이 존재할 확률이 존재하기에 주의 바랍니다.
- 잘못된 내용, 오타는 지적해 주시면 감사하겠습니다.
강의링크:
https://www.youtube.com/watch?v=YAgjfMR9R_M&list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r&index=13
강의자료:
https://web.eecs.umich.edu/~justincj/slides/eecs498/498_FA2019_lecture13.pdf
seq2seq & Attention

위 그림은 이전시간에 배운 RNN을 사용하여 Enocder & Decoder로 번역을 진행하는 seq2seq입니다.
기계번역에 주로 사용되고, 아래의 영어를 스페인어로 번역하는 예시입니다.
we are eating bread → estamos comiendo pan
Enocder의 hidden state는 t 시점의 input, t-1 시점의 hidden state와 가중치 행렬곱을 진행한 후, tanh 활성화함수를 통과하여 만들어집니다.
Decoder의 s_t는 t-1 시점의 output, t-1 시점의 Encoder의 hidden state, context vector를 통해 만들어집니다.
*Encoder + context vector 구조 = Decoder 구조
이때 context vector는 sequence를 요약한 내용으로 Decoder의 매 step에 입력합니다. 그리고 context vector의 길이는 고정되어 있습니다. 하지만 RNN을 사용한 Sequence-to-Sequence에는 문제가 있습니다.
sequence가 길어지면 이를 고정된 크기의 context vector로 요약하기 힘들다는 점입니다.
→ 따라서 매 step의 decoder에 새로운 context vector를 사용합니다.
Problem: Input sequence bottlelenecked through fixedsized vector. What if T=1000?
Idea: use new context vector at each step of decoder!

seq2seq를 RNN만으로 진행하면 생기는 문제를 해결하기 위해 Attention을 도입하였습니다. Attention은 말 그대로, '주목'하는 것입니다.
e_t, i는 t-1 시점의 s와 t 시점의 hidden state를 토대로 계산되며, 이를 softmax를 통해 합이 1인, 0 < a_t, i < 1로 바꿔줍니다. a_t, i는 어디에 사용될까요? 바로 context vector를 계산하는 데 사용됩니다. RNN의 문제를 해결하기 위해 RNN with Attention에서는 매 시점마다 새로운 context vecotr를 사용한다고 했기 때문입니다.
t 시점의 context vector, c_t는 a_t, i와 h_i의 linear combination으로 계산됩니다. 이를 직관적으로 설명하자면, Decoder의 t 시점을 구성하는데, Encoder의 각 부분이 얼마큼 중요한지를 의미합니다.
스페인어 "estamos"는 영어 "we are"에 대응합니다. 따라서 a_11(we)와 a_12(are)는 각각 0.45의 중요도를, a_13(eating)와 a_14(bread)는 각각 0.05의 중요도를 가집니다. 다른 단어를 예측할 때는 또 중요도가 바뀌겠지요?

다음 단어인 comiendo를 예측하기 위해 s_2를 계산할 때는 먼저, 중요도 + s_1을 통해 c_2를 계산하고, s_1, c_2, y_1을 바탕으로 s_2를 계산합니다.

단어별 attention 값들을 보여준 것입니다. 대응하는 단어들의 attention 값이 높음을 확인 가능합니다. 초록 박스를 보시면, 순서가 달라진 것을 확인할 수 있습니다. 순서가 달라도 잘 작동한다는 것은 큰 장점이 있는데요, 언어와 언어 간 문장 구조가 다를 수 있기 때문입니다. 나아가 다른 분야에도 사용 가능함을 의미합니다. 마지막으로 시각화 가능한 attention을 통해 모델이 학습하는 방법을 이해할 수 있게 되었습니다.
Image Captioning

Decoder는 hidden state의 순서를 고려하지 않습니다. 따라서 텍스트 말고도 attention이 필요한 항목들에 사용 가능합니다. 이러한 이유로 텍스트가 아닌 다른 시계열에서 attention을 사용하는 것 같습니다. 위처럼 이미지도 가능합니다.

각 단어가 이미지의 어떤 부분에 대응하는지도 파악 가능합니다.
Attention Layer
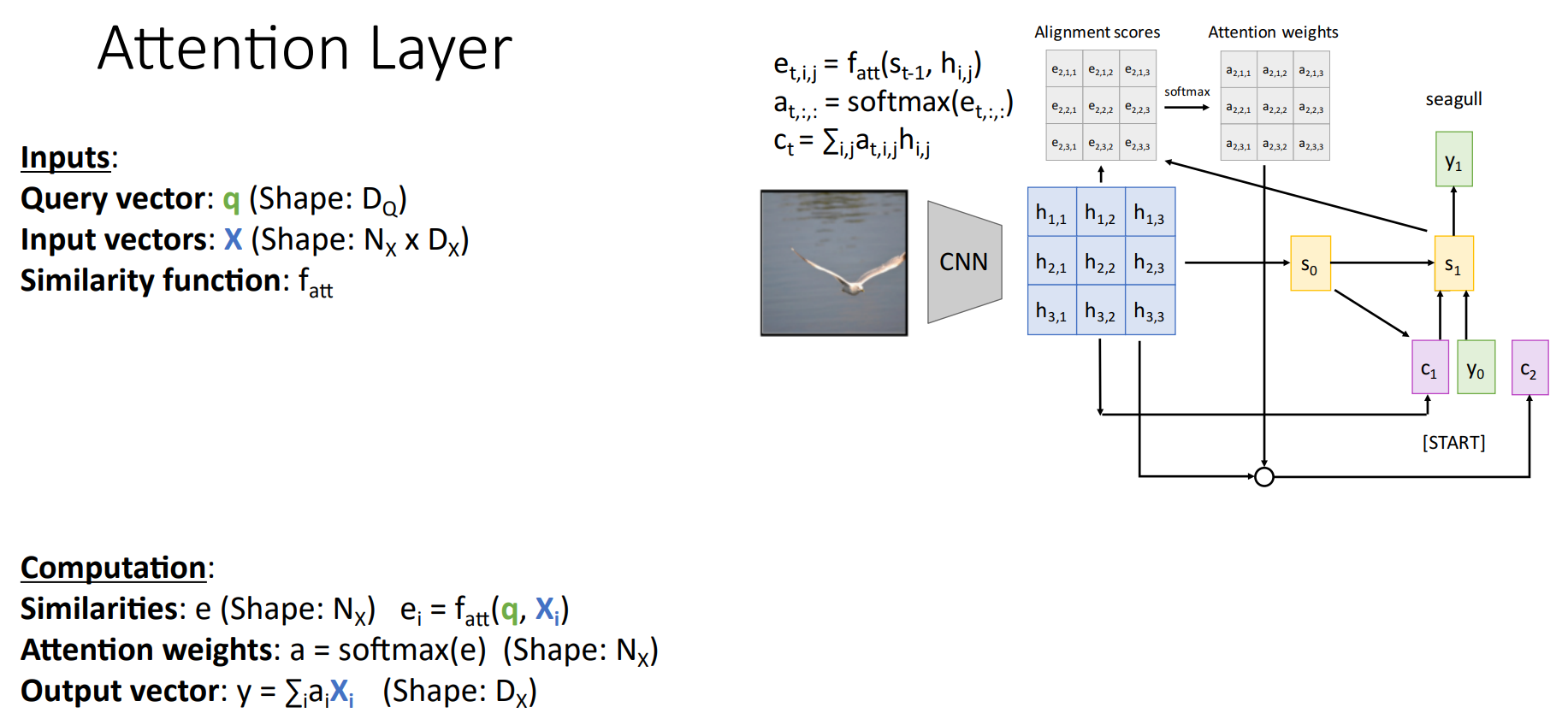
Inputs
- Query vector(decoder의 hidden state
- Input vectors(: encoder의 hidden states
- Similarity function(: query vector와 input vector의 유사도를 파악하여 중요도 계산

Similarity function을 조금 더 편하게 계산한 dot product로 → dot proudct값이 sqrt(D_Q)로 scaling 한 scaled Dot product → key, query, value를 활용하여 위와 같은 최종 식을 도출하게 되었습니다.
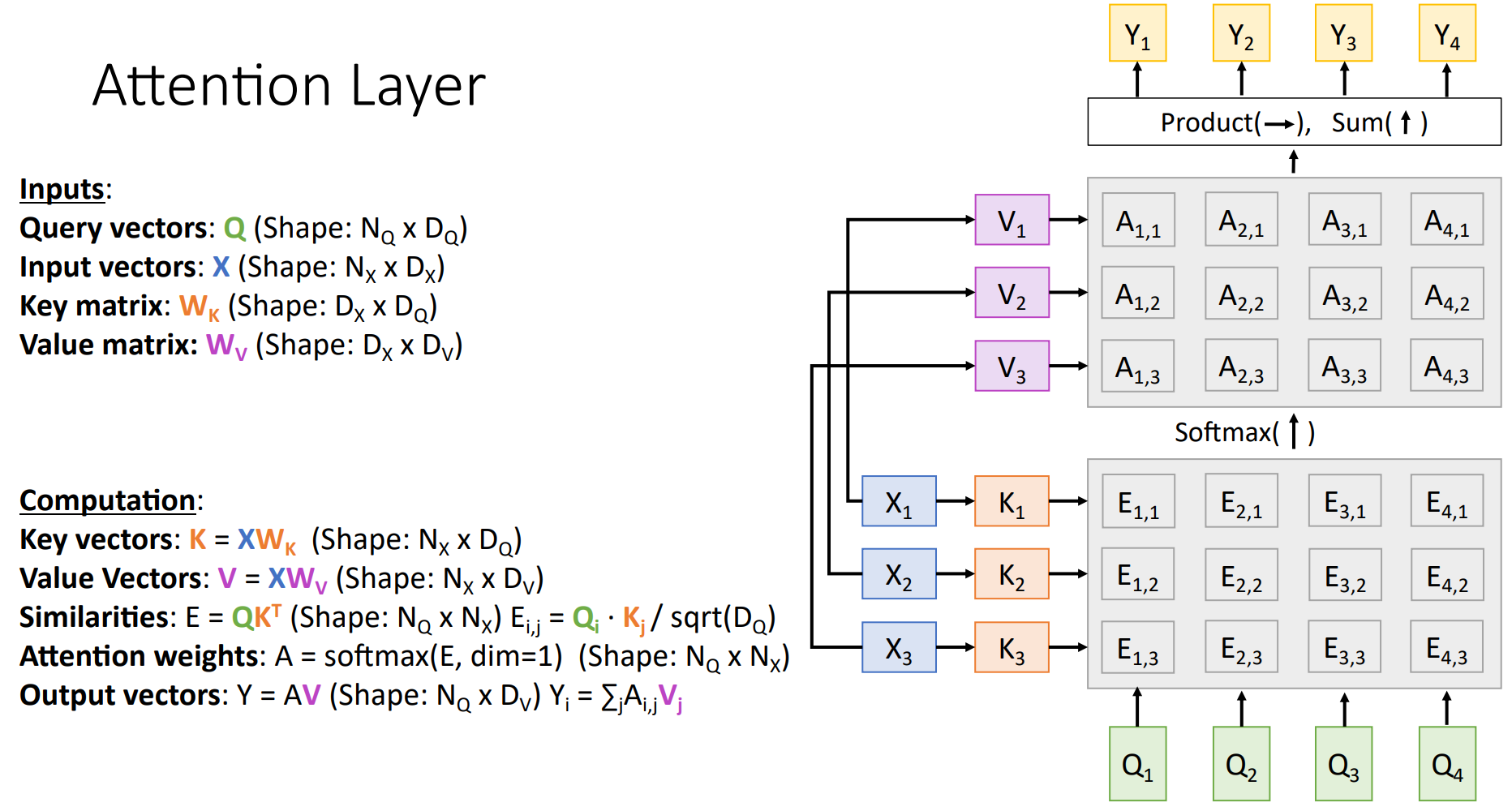
Self-Attention Layer

Self-Attention은 Attention layer의 특별한 case로, 하나의 시계열 데이터 내에서의 attention입니다. 예를 들어 we are young이 있을 때, we가 are, young과 각각 어떤 관계를 맺는지 attention 하는 것입니다.
Self-Attention Layer에서 input vector의 순서를 바꾸는 permuting을 적용해 볼 수 있는데, permuting을 진행하면 query, value, output의 각 vector는 동일하지만, 순서는 바뀐 상태입니다. s(): permutation, f(): self-attention일 때, 다음 식이 성립합니다.
이는 Self-Attention Layer가 input의 순서에 영향을 받지 않음을 의미합니다.
하지만 기계 번역과 같이 순서가 중요한 경우에는, positional encoding을 통해 순서를 인지합니다.
Masked Self-Attention Layer

다음 단어를 예측하기 위해서는 사전에 입력된 정보만 활용해야지, 미래 정보도 활용해서는 안됩니다. 따라서 미래 정보를 masking 하는 layer입니다. 첫 번째 word를 예측할 때는 첫 번째 word를 제외한 자리에는 음의 무한대를 넣어 softmax를 진행하면 값이 0이 나오도록 만들고, 두 번째 word를 예측할 때는 첫 번째, 두 번째 word를 제외한 자리에 음의 무한대를 넣는 방법으로 진행됩니다.
Multihead Self-Attention Layer

Transformer가 소개된 'Attention is All you Need' 정리글입니다. 참고하시고, 복습하시면 큰 도움이 될 것입니다 : )
https://life-ai-learning.tistory.com/7
[논문 정리] Attention Is All You Need
본 게시글은 Attention Is All You Need 정리글입니다. 개인적인 생각이 서술되어 있습니다. 잘못된 내용이 존재할 확률이 존재하기에 주의바랍니다. 잘못된 내용, 오타는 지적해주시면 감사하겠습니
life-ai-learning.tistory.com
저도 잘 이해를 하지 못하여 부족한 부분이 많습니다.
제대로 이해한 다음에 다시 돌아오겠습니다.
'공부 정리 > Machine learning & Deep learning' 카테고리의 다른 글
| [EECS 498-007 / 598-005] Lecture 20: Generative Models II (1) | 2023.02.22 |
|---|---|
| [EECS 498-007 / 598-005] Lecture 19: Generative Models I (0) | 2023.02.15 |
| [EECS 498-007 / 598-005] Lecture 12: Recurrent Neural Networks (0) | 2023.02.08 |
| [EECS 498-007 / 598-005] Lecture 11: Training Neural Network (0) | 2023.02.01 |
| [EECS 498-007 / 598-005] Lecture 8: CNN Architectures (0) | 2023.01.26 |



