- 본 게시글은 Attention Is All You Need 정리글입니다.
- 개인적인 생각이 서술되어 있습니다. 잘못된 내용이 존재할 확률이 존재하기에 주의바랍니다.
- 잘못된 내용, 오타는 지적해주시면 감사하겠습니다.
Reference
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30. / APA style
Abstract
Sequence 변환에 있어 encoder + decoder로 이루어진 recurrent, CNN이 사용되어 왔습니다.
가장 좋은 성능을 보이는 모델 또한 encoder + decoder를 사용한 attention mechanism이었습니다.
본 논문에서는 새로운 구조를 제안하려고 합니다.
'Transformer'
Recurrent, CNN 없이, 오직 attention mechanism만 사용할 것입니다.
English → German & English → French,
2가지 번역 실험을 통해 성능을 검증해보았고, state of the art(이하 SOTA, 현재 가장 최고수준)을 달성하였습니다.
정리: 성능이 우수한 Transformer를 제안하고자한다.
1. Introduction
Sequence 모델링, 변환 문제(언어 모델, 기계 번역)에서 RNN(Recurrent neural networks), LSTM(long short-term memory), Gated RNN이 SOTA를 달성해왔습니다.
하지만 Recurrent model에는 치명적인 단점이 존재하는데요,
'병렬화가 불가능, sequence가 길어질수록 치명적'이라는 것입니다.
→ 병렬화가 불가능하다는 것은 한 번에 처리가 불가능하고, 순차적으로 입력을 해야함을 뜻합니다.
따라서 sequence가 길어질수록 작업량 & 작업 시간은 늘어나게 됩니다.
다행히 최근 연구에서는 factorization tricks, conditional computation으로 개선이 되었지만, 근본적인 문제는 여전히 남아있습니다.
Attention mechanism은 sequence 모델링, 변환 문제에서 많이 사용되었고, 또한 Input과 Output 길이를 신경쓰지 않아도 됩니다. (길이가 정해져 있지 않기에, 억지로 압축을 할 필요가 없음)
하지만 여전히 Recurrent network와 함께 사용되어왔습니다.
Transformer는 recurrence를 사용하지 않고, attention mechanism에 전적으로 의존합니다. 병렬화가 가능해 작업 시간을 줄일 수 있었고, 이는 SOTA 달성을 가능하게 헀습니다.
정리: Recurrent의 단점에도 불구하고 attention mechanism은 recurrent와 함께 사용되어왔음. Transformer는 attention mechanism만을 사용할 것임!
2. Background
Sequential 계산을 줄이는 것은 CNN basic building bock을 사용하는 Extended Neural GPU, BtyeNet, ConvS2S에서도 사용되었습니다. 하지만 Input과 Output의 dependency를 학습하기에는 어려움이 있습니다.
Transformer에서는 상수 시간의 작업량으로 줄어듭니다.
Self-attention(intral-attention)은 sequence의 표현을 계산하기 위해 single sequence의 다른 위치와 관련된 attention mechanism입니다.
End-to-end는 recurrent attention mechanism에 기반을 두고 있고, 간단한 Q&A에 좋은 성능을 보입니다.
정리: Transformer는 self-attention에 주목한 첫 번째 model이다!
3. Model Architecture

Encoder
- N=6인 개별적인 identical layer로 구성되어있습니다.
- 각 layer는 2개의 sub-layer, multi-head self-attention + feed forward로 이루어져있습니다.
- Sub-layer의 output은 LayerNorm (x + Sublayer(x))입니다.
- Resiudual connection(잔차 연결)을 구현하기 위해 embedding layer 및 output이 차원은 512입니다.
Decoder
- N=6인 개별적인 identical layer로 구성되어있습니다.
- Encoder에 있는 sub-layer( multi-head self-attention + feed forward)에 세 번째 sub-layer가 추가되었습니다.
- Encoder와 마찬가지로 Residual connection을 구현합니다.
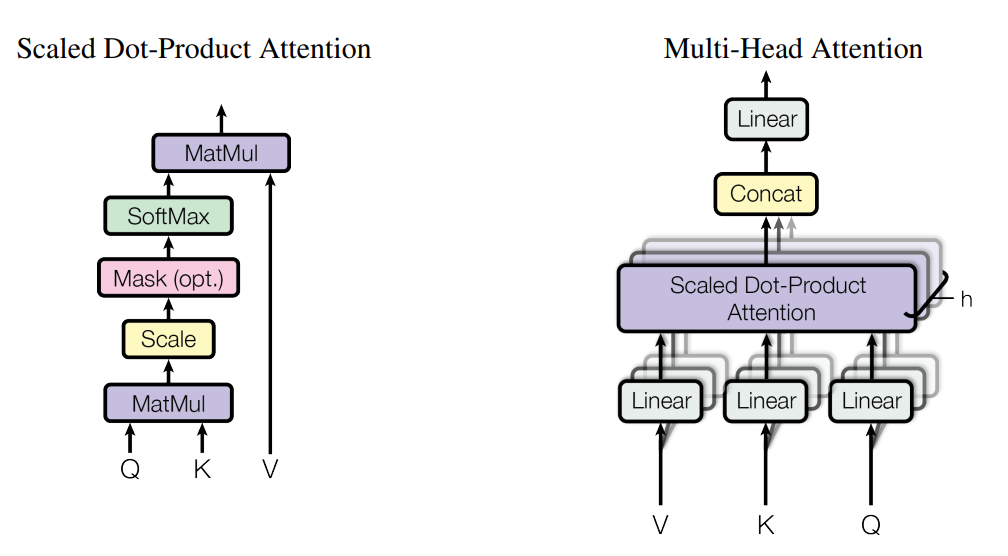
Attention
- Query and key-value set을 ouput에 mapping 하는 것으로 묘사가능합니다.
- Scaled Dot-Product Attention 계산은 다음과 같습니다.
이를 풀어쓰면, Query와 key를 내적한 값을, key의 차원에 루트 쓴 값으로 scaling 합니다. 이를 softmax를 통해 정규화한 뒤, value를 곱해 최종적인 attention 값을 구합니다.
* '나는 최고다'는 문장을 떠올려봅시다. Query는 '나', Key는 '나', '는', '최고다'가 될 수 있습니다.
Query와 각 Key와의 관계를 score한 뒤, value를 곱한 것입니다. 이때 h번 반복한다는 뜻은 서로 다른 Query, Key, Value를 통해 다방면에서 학습한다는 뜻입니다. (저는 나 / 나는 등 단어의 크기, 중요도 등을 다르게 함으로 이해했습니다)
* 내적을 통해 유사한 방향으로 향하고 있는지 확인할 수 있습니다.
- Multi-head attention은 single attention보다 h번 key, key&value의 차원에 각각 사영한 서로 다른 값들을 합치는게 더 효과적임을 통해 나왔습니다. 다각도로 바라보는 것이 더 효과적이라는 뜻 같습니다. 논문에서는 h=8로 설정하였는데, model의 차원 / h (512 / 8 = 64)로 차원을 낮추었고 이는 총 계산 비용이 single-head attention과 비슷하다는 뜻입니다. 즉 비용은 비슷하지만 성능은 더 좋아졌다는 뜻입니다. / Multi-Head Attention은 나누어진 attention들을 다시 Concat해야하기 때문에, model의 차원을 동일하게 유지하려면 h와 차원은 반비례하게 됩니다.
- Position-wise Feed-Forward Networks: 각 encoder & decoder는 모두 연결된 feed-forward layer를 지닙니다. ReLU 활성화함수를 통해 2번의 선형 변환을 합니다. 수식으로 표현하면 다음과 같습니다.
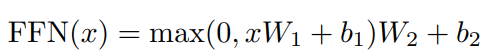
이때 model(input, output)의 차원은 512, inner-layer의 차원은 2048입니다.
- Embeddings and Softmax: 학습된 embedding을 input token과 output token을 d_model 차원으로 전환하기위해 사용합니다. 또한 two embedding later와 pre-softmax 선형변환에 같은 weight matrix를 사용합니다. Embedding layers에서는 여기에 d_model의 제곱근을 곱합니다.
- Positional Encoding: 제안한 model에서는 recurrence와 convolution을 사용하지 않습니다. 그러므로 sequence의 순서를 만들기 위해 상대적 or 절대적 위치에 관한 정보를 추가해야합니다. Positional encodings를, encoder & decoder stack의 맨 아래에 있는 input embeddings에 추가합니다. Positional encodings의 차원은 d_model과 동일합니다. 그러므로 이들에관한 연산을 수행할 수 있습니다.
*순서가 없는 model matrix에 postion을 보여주는 matrix를 더하여 순서를 생성하는 느낌입니다.
4. Why Self-Attention
Self-attention을 사용하는 이유는 다음과 같습니다.



