- 본 게시글은 Continual Learning with Deep Generative Replay 정리글입니다.
- 개인적인 생각이 서술되어 있습니다. 잘못된 내용이 존재할 확률이 존재하기에 주의 바랍니다.
- 잘못된 내용, 오타는 지적해 주시면 감사하겠습니다.
Reference
- Shin, H., Lee, J. K., Kim, J., & Kim, J. (2017). Continual learning with deep generative replay. Advances in neural information processing systems, 30. / APA style
Continual Learning에 대한 이해가 있어야 본 논문을 이해할 수 있습니다. Continual Learning에 관해 잘 정리한 아래의 블로그를 잠시만 방문하고 오시길 바랍니다.
https://engineering-ladder.tistory.com/94
Continual Learning의 원리와 연구 Trend
Machine Learning을 5G/6G 통신이나 Image Processing 등 여러 Domain에 적용하는 사례가 늘어나고 있다. 하지만, 단순히 AI를 적용했다의 의미를 넘어서, 실용성이 있기 위해서 넘어야 하는 허들이 몇 가지 있
engineering-ladder.tistory.com
Abstract
- 여러 task를 수행할 수 있는 인공 지능의 구현은, catastrophic forgetting로 어려움을 겪음
- 이전 데이터를 replay 하면 문제가 완화, but 대용량 메모리 필요 & 과거 데이터에 대한 접근 제한으로 불가능한 경우가 많음
- 해마의 생성적 특성에서 영감을 받아 생성 모델 generator & task를 해결하는 solver 구조를 갖춘 Deep Generative Replay를 제안
- generator & solver만으로 이전 task의 학습용 데이터를 쉽게 만들고 새로운 task 대한 데이터와 맞출 수 있음
정리: catastrophic forgetting로 continual learning 어려움 → generator & solver로 구성된 Deep Generative Replay를 제안
Introduction
인간 & 영장류는 지속적으로 새로운 능력을 배우고 지식을 축적하는 독특한 능력이 있습니다. 게다가 영장류는 과거 기억을 심각하게 왜곡하지 않으면서, 새로운 정보를 통합하고 인지 능력을 확장합니다.
그러나 DNN(deep neural network)에서의 continual learning은 이전에 학습한 작업에 대한 모델 성능이 새로운 작업에 대해 훈련될 때 갑자기 저하되는 catastrophic forgetting 어려움을 겪습니다. 인공 신경망에서 input은 파라미터의 output과 일치합니다. 따라서 새로운 task를 훈련하면서 이전 지식을 거의 잊어버릴 수 있습니다. 이러한 문제는 순차적으로 다중 작업을 하는 DNN의 continual learning에 핵심적인 장애물이었습니다.
*catastrophic forgetting: 이전 task에서 뛰어난 성능을 보인 모델이 다른 task에서는 성능이 현저히 떨어지는 현상
*task: 이전 task는 학습한 데이터, 현재 task는 학습할 데이터를 지칭
정리: 인간은 continual learning 가능, 그러나 인공신경망은 어려움
catastrophic forgetting을 완화하려는 시도는 과거 데이터를 저장하는 episodic 기억 시스템에 의존했습니다. 저장된 것은 새 작업에서 추출한 실제 샘플과 함께 정기적으로 replay 되며 네트워크 파라미터는 공동으로 최적화됩니다. 이러한 방식으로 훈련된 네트워크는 각 작업에 대해서만 훈련된 별도의 네트워크와 마찬가지로 수행되지만, 과거 입력을 저장하고 재생하기 위해 많은 작업 메모리가 필요하다는 것입니다. 또한 이러한 데이터 저장 및 재생은 일부 실제 상황에서는 실행 가능하지 않을 수 있습니다.
정리: catastrophic forgetting 문제를 해결하기 위해 이전에 시도한 방법: 축적된 정보를 저장 & 새로운 정보와 함께 훈련하는 것. but 엄청난 메모리를 필요 & 때로는 불가능
인간 & 영장류는 제한된 경험에서도 새로운 지식을 습득 및 과거의 기억을 유지합니다. 영장류의 뇌와 인공 신경망의 차이점은 분리되어 상호 작용하는 메모리 시스템의 존재입니다. 보완 학습 시스템(CLS) 이론은 해마와 신피질을 포함하는 이중 기억 시스템의 중요성을 설명합니다. 해마 시스템은 최근의 경험을 빠르게 부호화하며, 짧은 기간 동안 지속되는 기억 흔적은 수면 중 또는 의식 및 무의식 회상 중에 재활성화됩니다. 기억은 인코딩 된 경험의 다중 재생과 동기화된 활성화를 통해 신피질에서 통합됩니다. 강화 학습 에이전트 훈련에서 경험 재생의 사용에 영감을 준 메커니즘입니다.
정리: 영장류의 뇌와 인공 신경망의 차이점: 별도의 상호 작용하는 기억 시스템의 존재. 영장류의 뇌에서 해마가 지속적으로 기억을 재활성화.
최근 연구 결과에 따르면, 해마가 단순히 경험을 replay 하는 buffer 역할 이상을 한다고 합니다. 기억 흔적의 재활성화는 다소 유연한 결과를 낳습니다. 재활성화를 변경하면 통합된 기억에 결함이 발생하는 반면, 해마의 특정 기억 흔적을 공동 자극하면 경험하지 않은 잘못된 기억이 생성됩니다. 이러한 특성은, 해마가 replay buffer보다 generative 모델과 더 잘 일치함을 시사합니다. 특히 deep Boltzmann 기계 또는 VAE와 같은 deep generative 모델은 관찰된 입력과 거의 일치하는 고차원 샘플을 생성할 수 있습니다.
정리: 해마는 replay buffer보다 generative(생성) 모델에 가까움.
본 논문은 과거 데이터를 참조하지 않고 DNN을 순차적으로 훈련시키는 방법을 제안합니다. deep generative replay에서 모델은 생성된 pseudo 데이터의 replay를 통해 이전에 획득한 지식을 유지합니다. 특히 과거 데이터를 모방하기 위해 GAN(Generative Adversarial Networks)에서 deep generative 모델을 훈련합니다. 생성된 데이터는 과거 작업을 나타내기 위해 과거 작업 solver의 응답과 쌍을 이룹니다.
scholar 모델 = generator & solver은 필요한 만큼 가짜 데이터와 요구되는 대상 쌍을 생성할 수 있으며, 새 작업이 제시되면 생성된 쌍에 새 데이터가 삽입되어 generator 및 solver 네트워크를 업데이트합니다. 따라서 scholar 모델은 자신의 지식을 잊지 않고 새로운 작업을 학습하고 네트워크 구성이 다른 경우에도 생성된 input-target 쌍으로 다른 모델을 가르칠 수 있습니다.
정리: 과거 데이터를 저장하는 기존의 방법에서 과거 데이터를 저장하지 않아도 되는 방법, scholar 모델을 제안. scholar 모델은 generator와 solver로 구성.
scholar 네트워크에서 지원하는 deep generative replay는 실제 과거 데이터가 없어도, 지식을 유지할 수 있으므로 (개인 정보 보호 문제와 관련된) 다양한 실제 상황에 사용될 수 있습니다. GAN의 발전으로 훈련된 모델이 다양한 도메인에서 실제 데이터 분포를 재구축할 수 있게 되었습니다. 비록 이미지 분류 작업에서 모델을 실험했지만, 이 모델은 훈련된 generator가 안정적으로 input space를 재생산하는 한 어느 작업에서나 사용할 수 있습니다.
정리: 과거 데이터 없이, 다양한 도메인에서의 실제 데이터 분포를 재구축 가능. ex) A 모델에 고양이 / 개 분류, 숫자 분류 등 다양한 도메인 학습되어 있을 수 있음.
Related Works
1. Comparable methods
연구들은 과거 데이터를 현재 task에서 접근하지 못하는 상황을 가정합니다. 이러한 연구는 가중치에 대한 변화를 최소화하면서 네트워크 매개변수를 최적화하는 데 중점을 둡니다. regularization 방법(dropout, L2 등)은 새로운 학습의 영향을 줄입니다. 나아가 EWC(elastic weight consolidation)는 이전 작업의 중요도에 따라 weight를 보호하면 성능 손실을 완화할 수 있음을 보여줍니다.
정리: 과거 데이터를 사용하지 못하니 regularization, EWC로 학습된 모델의 변형을 최소화하였다.
여러 task를 수행하는 DNN을 순차적으로 훈련하려는 시도는, task-specific 파라미터로 네트워크를 확장하여 catastrophic 간섭을 줄였습니다. input에 가까운 layer는 보편적인 특징을, output에 가까운 layer는 task-specific 한 특징을 포착합니다. output layer가 이전 layer로부터 간섭이 적긴 하지만, 이전 layer를 변경하면 여전히 약간의 성능 손실이 발생합니다. LwF(Learning without Forgetting)는 공유 네트워크 파라미터의 변경을 최소화하면서, 이미지 분류 작업에서 순차적 학습 문제를 해결합니다. fine-tuning 이전의 새로운 작업 입력에 대한 네트워크의 output은 이전 작업에 대한 지식을 나타내며 학습 프로세스 전체에서 유지됩니다.
정리: fine-tuning이전의 작업(공유 네트워크)의 변경은 최소화하고, task-specific 한 파라미터(각 task별로 파라미터를 fine-tuning 하거나 추가)만 변경하였다.
2. Complementary Learning System(CLS) theory
catastrophic forgetting을 완화하기 위해 보완적인 네트워크 구조를 설계하였습니다. 이전 작업에 대한 training 데이터에 접근할 수 없는 경우, 메모리 네트워크에서 생성된 pseudo-input 및 pseudo-target만으로 네트워크를 학습합니다. pseudorehearsal 기술이라고 하는 이 방법은 실제 데이터에 접근하지 않고 이전 input-output 패턴을 유지한다고 주장합니다. 두 개의 이진 패턴을 결합하는 것처럼 간단할 때는 단순히 random 노이즈 & 이에 맞는 response만으로 충분합니다. 그러나 추가적인 supervision 없이 의미 있는 고차원 pseudoinputs을 생성하는 것이 어렵기 때문에, 확장성을 입증하지 못했습니다.
3. Deep Generative Models
생성 모델은 관찰 가능한 샘플을 생성하는 모든 모델을 말합니다. 특히 생성된 샘플이 실제 분포에 있을 가능성을 최대화하는 DNN에 기반한, deep 생성 모델을 사용합니다. VAE 및 GAN과 같은 일부 심층 생성 모델은 이미지와 같은 복잡한 샘플을 모방할 수 있습니다.
GAN은 generator G와 a discriminator D 사이의 zero-sum 게임을 정의합니다. discriminator는 두 데이터 분포를 비교하여 실제 샘플에서 생성된 샘플을 구별하는 방법을 배우는 반면, generator는 실제 분포를 가능한 한 가깝게 모방하는 방법을 학습합니다. 두 네트워크의 목적함수는 다음과 같이 정의됩니다.

정리: GAN을 중심으로 Deep 생성 모델 설명
Generative Replay
잠시 용어를 정리하고 가겠습니다. continual learning에서 학습할 task 순서를 다음과 같이 정의합니다.
작업 순서: T = (T_1, T_2, · · · , T_N ) of N tasks.
Definition 1: 작업 T_i는 (x_i, y_i)의 데이터로, 분포 D_i에 대해 모델을 최적화하는 것
새로운 작업을 학습하고 다른 네트워크에 지식을 가르칠 수 있는 모델을 scholar라고 부릅니다. scholar는 네트워크가 가르치거나 배우기만 하는 앙상블 모델의 teacher-student의 개념과 다릅니다.
Definition 2: scholar H는 <G, S>의 tuple입니다. generator G는 실제와 같은 샘플을 생성하는 생성 모델, solver S는 θ를 파라미터로 하는 task를 해결하는 모델입니다.
solver는 작업 순서 T의 모든 작업을 수행해야 하기에, 전체 목적함수는 모든 작업 간에 편향되지 않은 sum loss를 최소화하는 것입니다.

정리: generator에서 모델을 생성하고, solver에서 task를 해결함. 이때 solver는 여러 task를 수행하므로 여러 task 전체를 고려한 loss가 최소화하는 것이 목적.
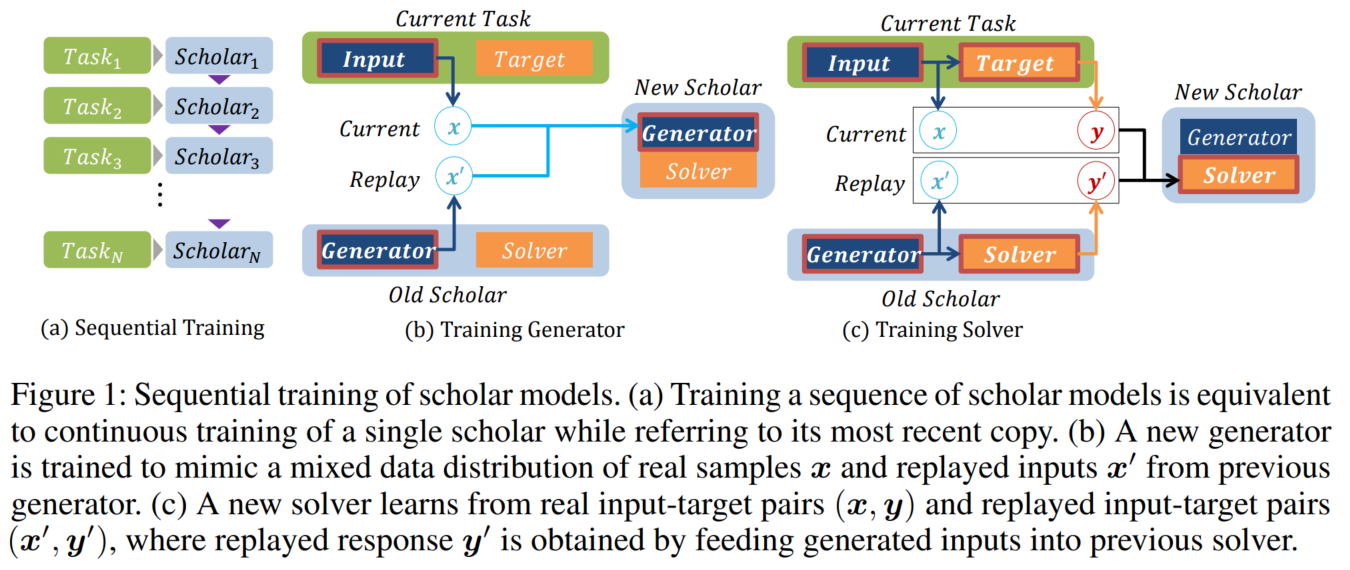
1. Proposed Method
scholar 모델에 대한 순차적 학습을 생각해 보면, 네트워크의 최근 copy를 참조하면서 single scholar 모델을 학습하는 것은, 순차적인 scholar 모델을 학습하는 것과 같습니다.
- H_n scholar 모델 = H_(n-1) scholar 모델 + 현재 task T_n을 학습하는 것
* Figure 1의 (a) 부분에 해당합니다.
다른 scholar로부터 온 새로운 scholar를 훈련시키려면, generator와 solver를 훈련시키는 두 가지 independent 한 절차가 필요합니다.
- 첫째, 새로운 generator는 현재 작업의 input x와 이전 작업에서 replayed 된 input x'을 받습니다.
- Real 및 replayed된 샘플은 이전 작업과 비교하여 현재 작업의 요구되는 중요도에 따른 비율로 mixed 됩니다.
- generator는 누적 input space를 재구축하는 방법을 학습하고, 새로운 solver는 실제 데이터와 replayed 된 데이터의 동일한 mix에서 나온 input과 target을 결합하도록 훈련됩니다.
- replayed target = replayed input에 대한 과거 solver의 output
- i번째 solver의 loss function은 다음과 같습니다.
* Figure 1의 그림의 (b), (c) 부분에 해당합니다.

θ_i: i번째 scholar의 네트워크 파라미터, r: real 데이터의 혼합 비율, original task에서의 모델 평가를 목표로 하기에 test loss와 training loss는 다릅니다.
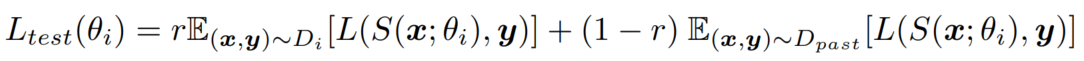
두 번째 loss term은 i = 1일 때 train, test loss function에서 모두 무시됩니다. 처음이기에 참조할 replayed 데이터가 없기 때문입니다. 참고로 D_past는 과거 데이터의 누적 분포입니다.
2. Preliminary Experiment
MNIST 데이터셋을 분류하는 모델로 예비 실험을 진행해 보았고, 결과를 통해 scholar 모델이 정보 손실 없이 지식을 전달하는 것을 관찰했습니다. 순차적인 scholar 모델은 이전 scholar의 generative replay를 통해 처음부터 훈련되었습니다. Accuracy가 유지됨을 확인 가능합니다.
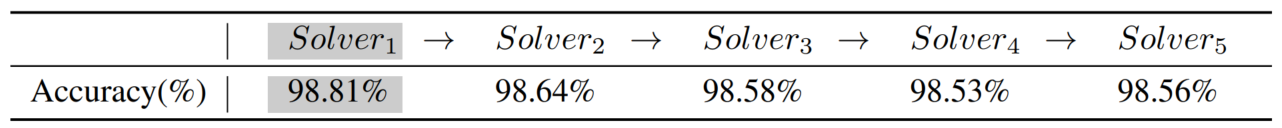
Experiments
이번 장에서는, 다양한 순차 학습에서의 generative replay 적용 가능성을 보여줍니다. 훈련된 scholar 네트워크 기반의 Generative replay는 다른 continual learning보다 우수합니다. Generative Replay로 네트워크를 훈련하는 것은, Generative 모델이 최적일 때 전체 데이터를 동시에 훈련하는 것과 동일합니다. 기본 실험으로 generative replay이 이전 작업이나 새로운 작업 모두에서 성능을 저하시키면서 순차적 학습을 하는지 실험합니다.
- 4.1에서는 forgetting의 정도를 조사하기 위해 독립적인 작업에 대해 네트워크를 순차적으로 훈련합니다.
- 4.2에서는 서로 다르지만 관련된, 두 도메인에서 네트워크를 훈련합니다. generative replay이 scholar 네트워크 설계에 대한 continual learning을 가능하게 할 뿐만 아니라, 다른 알려진 구조와의 호환성도 가능하다는 것을 보여줍니다.
- 4.3에서 scholar 네트워크가 메타 작업을 수행하기 위해 다양한 작업에서 지식을 수집할 수 있음을 보여줍니다.
1. Learning independent tasks
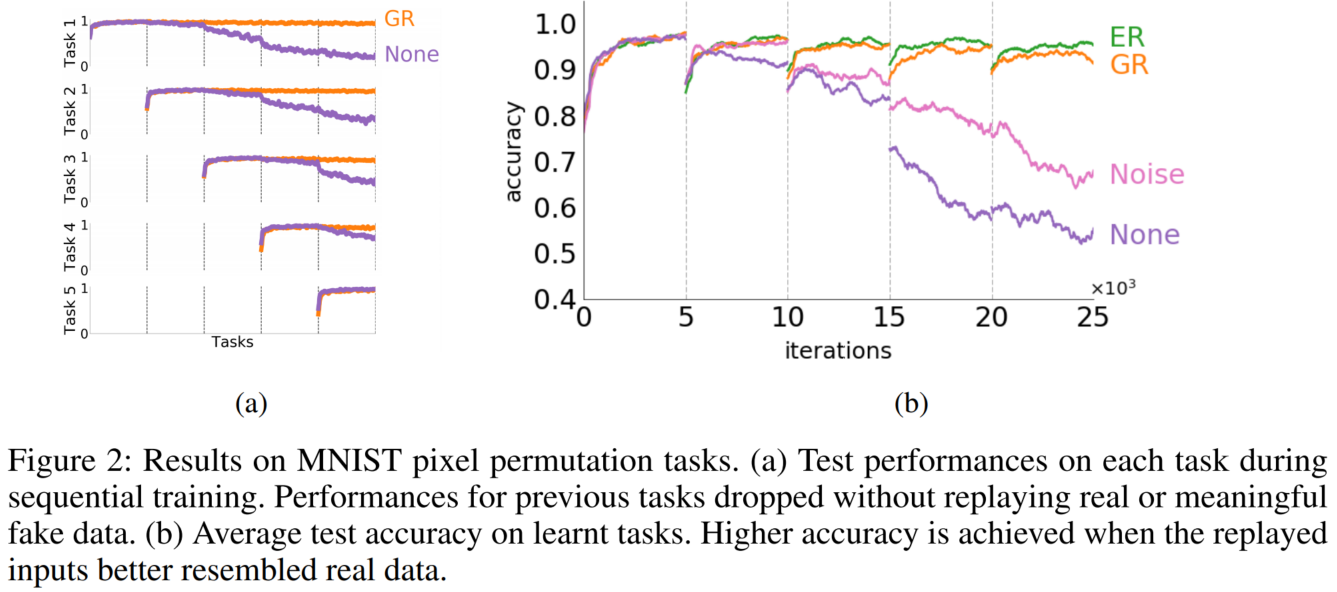
continual learning에서의 일반적인 실험은, MNIST데이터 이미지 분류 문제이지만, input 픽셀 값은 각각 고유한 무작위 순열 시퀀스로 섞습니다. solver는 순열 입력을 원래 클래스로 분류해야 합니다. (a)를 통해 replay의 효과를 확인 가능합니다.
2. Learning new domains
동일한 네트워크에서 독립적인 작업을 훈련하는 것은, 정보를 공유하지 않기 때문에 비효율적입니다. 따라서 모델이 여러 작업을 해결하는 데 도움이 되는 합리적인 설정에서 모델의 장점을 보여줍니다. 여러 도메인에서 작동하는 모델은 단일 도메인에서만 작동하는 모델에 비해 몇 가지 장점이 있습니다.
- 도메인이 완전히 독립적이지 않다면, 한 도메인에 대한 지식은 다른 도메인을 빠르고, 잘 이해하는 데 도움
- 다양한 영역의 일반화는 보지 못한 도메인에 관한 보편적인 지식 생성 가능
모델이 새로운 영역에 대한 지식을 generative replay과 통합가능한지 실험하기 위해, MNIST와 → SVHN(Street View House Number) 데이터 셋을 분류하는 모델을 순차적으로 훈련 및 SVHN → MNIST로 반대 방향도 훈련했습니다.
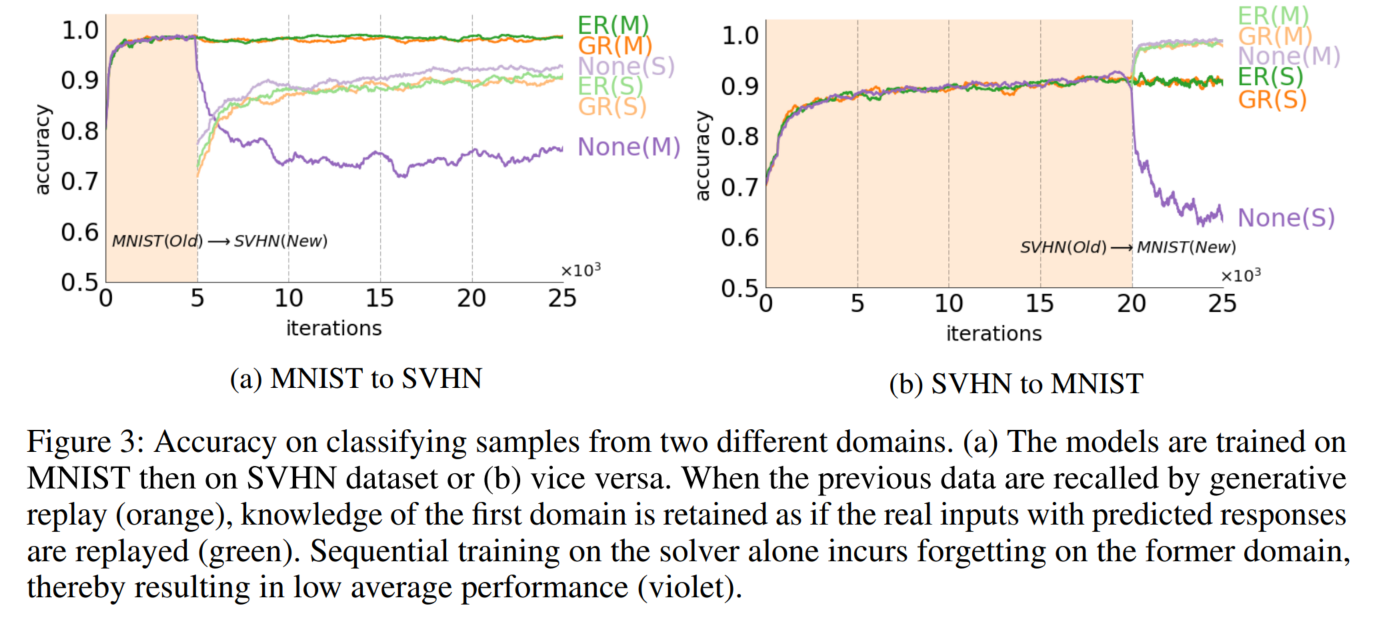

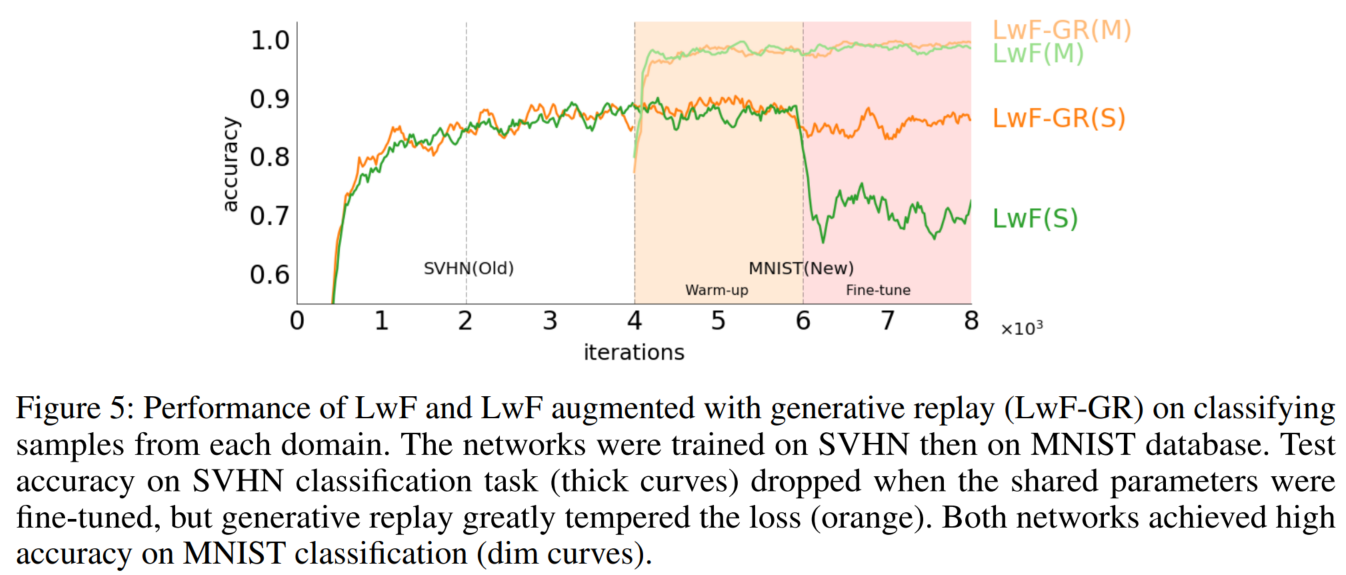
Figure 5에서는 LwF 알고리즘의 성능을 변형된 LwF-GR과 비교합니다. 원본 LwF 알고리즘으로 훈련된 solver는 fine-tuning이 시작될 때 공유 네트워크(녹색)의 변경으로 인해 첫 번째 작업에서 성능을 잃습니다. 그러나 generative replay을 활용한 네트워크는 대부분의 과거 지식(주황색)을 유지합니다.
3. Learning new classes
작업 간에 차이가 큰 경우에도, Generative replay가 과거 지식을 기억 잘하게 하기 위해 → 네트워크가 분리된 데이터에 대해 순차적으로 훈련되는 실험을 제안합니다. MNIST 데이터셋으로 실험했습니다.
인공 신경망을 클래스에서 독립적으로 훈련하는 것은, 새로운 작업의 분포로 변경될 수 있기에 어렵습니다. 따라서 이전 입력 및 목표 분포를 나타내는 입력 및 출력을 replay 하는 것은 균형 잡힌 네트워크를 훈련하는 데 필요합니다. 따라서 누적 실제 데이터의 입력 및 목표 분포가 복구되는지 여부의 관점에서 이 섹션의 앞부분에서 설명한 변형을 비교합니다.
- ER 및 GR 모델: input & target → 누적 분포 & 누적 분포
- noise 모델: input & target → 현재 분포 & 누적 분포
- none 모델: input & target → 현재 분포 & 현재 분포
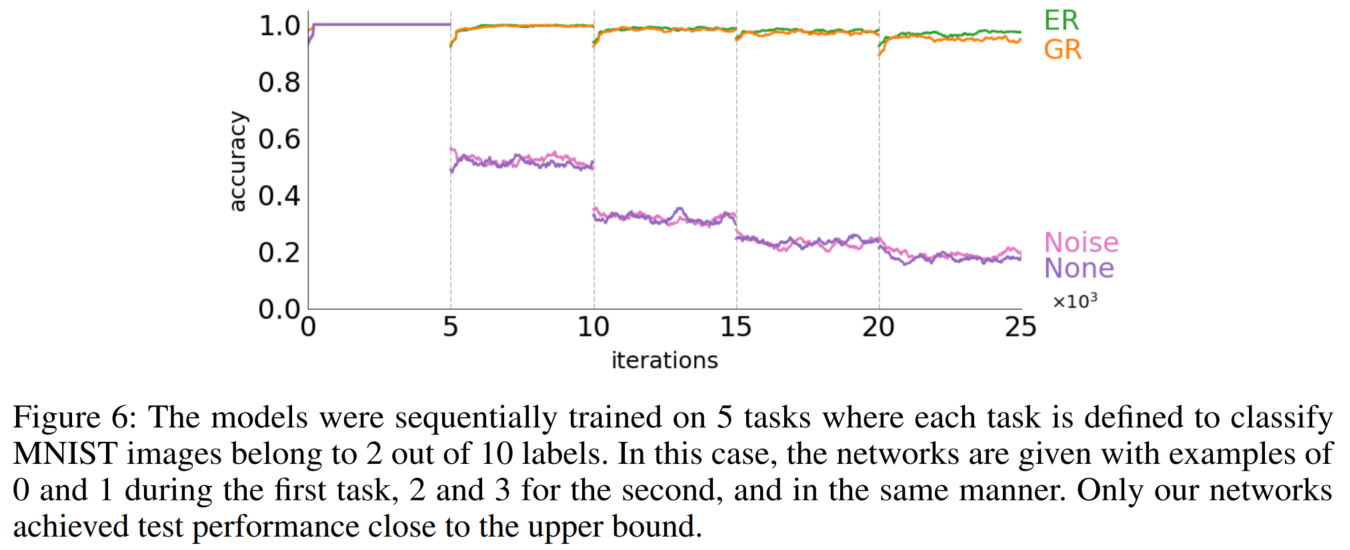
- Figure 6에서 MNIST 데이터 세트를 5개의 분리된 하위 집합으로 나눔, 각 하위 집합에는 2개 클래스의 샘플만 포함
- None(보라색): 부분집합에 대해 순차적으로 훈련될 때, 훈련된 분류기가 이전 클래스를 완전히 잊어버리고 데이터의 새로운 부분집합만 학습
- Noise(분홍색): 의미 있는 입력 분포 없이 과거 출력 분포만 복구하는 것은 과거 지시 유지에 도움 x
- GR(주황색): input & output 분포가 모두 재구성될 때 generative replay은 이전에 학습된 클래스를 불러일으켰고 모델은 모든 클래스를 구별

과거 데이터를 사용하지 못한다고 가정하기에, 현재 input과 이전 generator에서 생성된 샘플을 모두 모방하도록 generator를 훈련했습니다. 따라서 generator는 지금까지 만난 모든 예제의 누적 입력 분포를 재현합니다. Figure 7에서 볼 수 있듯이 훈련된 generator에서 생성된 샘플에는 발생한 클래스의 예가 동일하게 포함됩니다.
정리: 이전 task에서 학습한 class들을 다음 task에서도 재현 가능함. ex) task 1에서 0 학습 & task 2에서 1 학습 → task 3에서 0, 1 구현 가능!



