- 본 게시글은 Continual Learning for Anomaly based Network Intrusion Detection 정리글입니다.
- 개인적인 생각이 서술되어 있습니다. 잘못된 내용이 존재할 확률이 존재하기에 주의 바랍니다.
- 잘못된 내용, 오타는 지적해 주시면 감사하겠습니다.
Reference
Amalapuram, S. K., Tadwai, A., Vinta, R., Channappayya, S. S., & Tamma, B. R. (2022, January). Continual Learning for Anomaly based Network Intrusion Detection. In 2022 14th International Conference on COMmunication Systems & NETworkS (COMSNETS) (pp. 497-505). IEEE. / APA style
Abstract
- 사이버 공격으로부터 시스템을 방어하려면, 이상 기반 네트워크 침입 탐지 시스템(A-NIDS)이 지속적으로 발전해야 함
- 하지만 순차적으로 진화하는 작업을 적절하게 처리 x → 기계 학습 알고리즘을 비효율적으로 만듦
- 신경망은 순차 데이터를 학습할 때, catastrophic forgetting (CF) 발생하기 쉬움 → Continual Learning (CL)
- CL은 컴퓨터 비전에서 신경망 성능 개선에 효과적, but A-NIDS에 대한 적용은 아직 연구 x
- 본 논문에서 A-NIDS에서의 어려움을 해결하기 위해 CL의 적합성을 평가할 것임
- 컴퓨터 비전과 달리 네트워크 데이터세트는 클래스 불균형(CI) 문제가 있어 CL 알고리즘을 직접 적용하기 어려움
- 네트워크 데이터 세트에서 CL 알고리즘의 적합성 평가를 위해, 작업 순서에 대한 클래스 불균형의 영향 & 클래스 증분(CIL) 및 도메인 증분(DIL) 학습 설정에서 CL based A-NIDS 설계에 미치는 영향을 연구함
- 두 가지 CL 알고리즘 1. EWC(Elastic Weight Consolidation) 2. GEM(Gradient Episodic Memory)으로 CICIDS 및 KDD Cup'99 데이터 셋에 대해 평가
정리: 본 논문에서는, Continual Learning이 A-NIDS에 적합한지 평가해 볼 것임
INTRODUCTION
- 컴퓨팅은 컴퓨터, 가전 제품, 유틸리티, 센서등을 인터넷에 통합함으로써 유비쿼터스화되고 있음
- 통합으로 장치의 다양성과 데이터의 차원도 매우 빠르게 증가 & 연결된 장치의 취약성으로 인해 공격 환경도 증가
- 연결된 장치 훼손을 위해 취약성을 악용하는 행위를 네트워크 침투(penetration) 또는 침입(intrusion)이라고 함
- NIDS(Network Intrusion Detection System)는 네트워크 트래픽을 분석하여 정상적인 네트워크 동작('좋지 않음', '나쁨')을 따르지 않는 트래픽 패턴을 식별 & 침입 시도를 감지하는 데 사용됨
- NIDS는 misuse 또는 anomaly기반일 수 있음
- → misuse는 일련의 규칙 또는 알려진 signature을 사용하여 공격을 탐지
- → anomaly는 정상 활동과 이상 활동을 구별하는 결정 경계를 구획
정리: 장치가 연결됨에 따라 취약 & 공격 증가. NIDS를 활용하여 이를 감지. NIDS는 misuse or anomaly 기반
A. Motivation
ML을 사용하여 Anomaly based NIDS(A-NIDS) 시스템을 구축하는 것에는 문제가 있습니다.
- Evolving data stream: 진화하는 사이버 공격 및 zero-day 공격과 함께, 네트워크 트래픽이 스트리밍 방식으로 도착 → A-NIDS 모델은 지속적으로 학습(진화)해야 함
- Train with limited data and retraining cost: 재학습은 새로운 공격 데이터를 A-NIDS 모델에 통합하는 주기적인 과정. 재학습을 최적화하려면 이전 학습 데이터에 대한 액세스를 피해야 하기에, 최적의 A-NIDS는 사용 가능한 제한된(신규 공격) 데이터만으로 자동으로 학습해야 함
- Definition of normal data changing over time: A-NIDS는 시간 경과에 따라 네트워크에서 변하는 정상 트래픽의 특성을 인식해야 함
continually evolving A-NIDS를 구축하기 위한 이러한 모든 문제는 continual learning(CL)으로 해결 가능합니다.
정리: ML로 Anomaly based NIDS(A-NIDS) 구축에는 문제가 있음 → continual learning으로 해결 가능
B. Challenges and Contributions
본 논문은, continually evolving A-NIDS 구축과 관련된 다양한 문제를 식별 & 해결합니다.
- Catastrophic Forgetting(CF): CF는 학습한 지식을 망각하여 ML 기반 A-NIDS가 지속적으로 진화하는 특성을 방해함. CF에 관한 더 많은 통찰력을 얻기 위해, CSECICIDS2018 데이터 셋으로 실험 & CL을 사용하여 CF를 완화
- Class Imbalance (CI): CI는 많은 네트워크 데이터 셋(KDD Cup'99, CICIDS2017 등)에서 관찰되는 일반적인 문제이며, 이 문제를 무시하면 A-NIDS 효능을 저해할 수 있음. 본 논문은 CI 문제에 중점을 두고 실험 setting, CIL & DIL로 이를 해결
- Exploration: A-NIDS에 가장 적합한 방법을 발견하기 위해 서로 다른 클래스의 CL 알고리즘을 조사 & ANIDS의 가장 실용적인 설정에 적용할 수 있는 CL 알고리즘 클래스를 추천
정리: CI에 중점을 두고 A-NIDS가 지속적으로 진화할 수 있도록 CL을 적용
CONTINUAL LEARNING FOR ANOMALY DETECTION
non-stationary한 데이터 분포의 연속적인 stream에서 학습한 지식을, 획득하고 fine-tuneing 하는 것은 Continual Learning의 특징입니다. CL 기반 시스템의 학습 과정은 분명합니다. 작업을 점진적으로 학습하고 각 작업은 (x, y, t)으로 표시됩니다. x는 feature vector, y는 target vector, t는 tuple (x, y) ∼ P_t의 task descriptor입니다. 데이터의 연속체는 고정된 확률 분포 P(X, Y, T)에서 도출되지 않습니다. 즉, 순차 작업과 관련된 데이터는 non-iid입니다. 따라서 CL의 최종 목표는 (x, y) ~ Pt가 되도록 테스트 쌍 (x, t)와 관련된 대상 벡터 y를 예측하는 모델 f : X × T → y를 구성하는 것입니다.
A. Problem formulation
- 실제 환경에서 정상적인 트래픽 >> 공격 트래픽 → 트래픽 패턴의 차이는 클래스 불균형(CI)을 관찰의 잠재적인 이유
- 또한 최신 다중 레이블 공격 트래픽 데이터 셋은, 개인 정보 보호 문제로 사용이 어려움
- 위와 같은 이유로 침입탐지 문제를 다중 클래스 분류 문제로 formulate하는 것은 어려움 → 이상 탐지 문제로 설정함
- 실제 트래픽 시나리오와 유사하도록 이 작업에서 정상 and (or) 공격 트래픽 데이터를 결합하여 작업(t)을 형성
특정 작업 데이터(D_t)에 대한 훈련 시 다른 작업 데이터(D_o)에 대한 접근이 허용되지 않으므로, 목적 함수는 다음과 같습니다. x와 y는 각각 feature vector와 해당 target label(Benign 또는 Anomaly)입니다. fθ는 예측 함수를 나타내고 ℓ(.)은 손실 함수를 나타냅니다.

그러나 CF로 인해 학습의 질이 떨어질 수 있기에, 다양한 CF 회피 기법들이 고안되었습니다.
- Regularization 기반 방법: 새로운 입력 동안 값의 큰 변화를 피하기 위해 모델의 매개변수에 일부 제약을 적용
- Dynamic Architecture 방법: 기본 모델의 아키텍처 속성을 변경하여 작동
- Memory replay 방법: CF를 완화하기 위해 replay에 가장 관련 있는 정보를 저장하기 위한 캐시를 유지
CF 회피 기술을 적용한 식은 다음과 같습니다. R(φ)는 CF 회피 기술로 선택한 제약 조건입니다.

정리: 이상 탐지(이진 분류) 문제로 정의 & CF 회피 기법을 적용한 목적 함수 제시
B. Training Scenarios
CL 알고리즘의 서로 다른 클래스 성능 비교를 위한 공통 프레임워크를 설정하기위해, 세 가지 continual learning 시나리오가 제안되었습니다. 작업 ID가 제공되는지 여부, 그렇지 않은 경우 테스트 시간에 추론되어야 하는지 여부를 기반으로 합니다.
- TIL(Task Incremental Learning) 모드에서는 작업 ID가 항상 제공. 따라서 task-specific 요소를 학습할 수 있음
- DIL(Domain Incremental Learning) 설정에 대한 테스트 시간에는 작업 ID를 사용할 수 x, 당면한 작업을 해결할 것임
- CIL(Class Incremental Learning) 설정은 이전에 학습한 모든 과제를 해결하고 과제 정체성을 유추
본 논문에서는 CIL 및 DIL 설정을 사용합니다.
정리: TIL, DIL, CIL 설정 중 본 논문은 CIL, DIL 설정을 사용
LITERATURE REVIEW
CL의 발전은 주로 컴퓨터 비전 & 자연어 처리에서 일어났고, 네트워크 이상 탐지 영역서는 거의 발전이 이루어지지 않았습니다. CL 및 네트워크 이상 탐지 관련에 관한 사전 연구는 다음과 같습니다.
- VAE(Variational AutoEncoder) 기반 이상 탐지에서 catastrophic forgetting을 완화하기 위한 확장 방법
- VAE 기반의 CL 접근 방식을 사용하여 이미지 분류를 위한 방법
- 인간이 학습하는 방식(순차적 학습)과 기계가 학습하는 방식(경험적 위험 최소화 원리 사용) 사이의 격차를 최소화하려고 시도
- deep AutoEncoder로 차원이 높고 실측 정보가 부족한 데이터를 처리하기 위해 비지도 이상 탐지 기술을 고안
- 학습 데이터에서 잡음을 분리하고 학습에 사용된 cleaner 데이터를 사용하여 이상 탐지 효율성을 개선하려고 시도
- GAAL(Generative Adversarial Active Learning)를 사용, 인공 이상값을 생성하여 작동하는 이상 탐지 알고리즘 개발
- 클래스 균형을 유지하기 위해 메모리에 유지할 데이터 샘플을 제어하는 클래스 균형 저장소 샘플링 기술을 제안
정리: 사전 연구 설명
PROPOSED CL-BASED A-NIDS
이번 장에서는 제안된 CL based A-NIDS에 대한 개요를 보여줍니다. 이 아키텍처는 CL 기반 A-NIDS에 필요한 학습 및 추론 설정을 공동으로 나타냅니다. CL 모델을 학습하고 들어오는 트래픽 스트림(추론)을 분류하는 것은 두 가지 동시적 활동이며, 최고 성능 모델은 model selector 게이트웨이를 통해 inference engine (IE)에 배포됩니다. 들어오는 네트워크 데이터 스트림은, 분류에 필요한 기능을 추출하는 IE로 공급됩니다. 학습에 사용되는 A-NIDS 시스템의 두 가지 중요한 구성 요소는 Data Preprocessing Engine과 Continual Learning Modules입니다. 이를 각각 자세히 살펴보겠습니다.
제안하는 모델 구조는 다음과 같습니다.
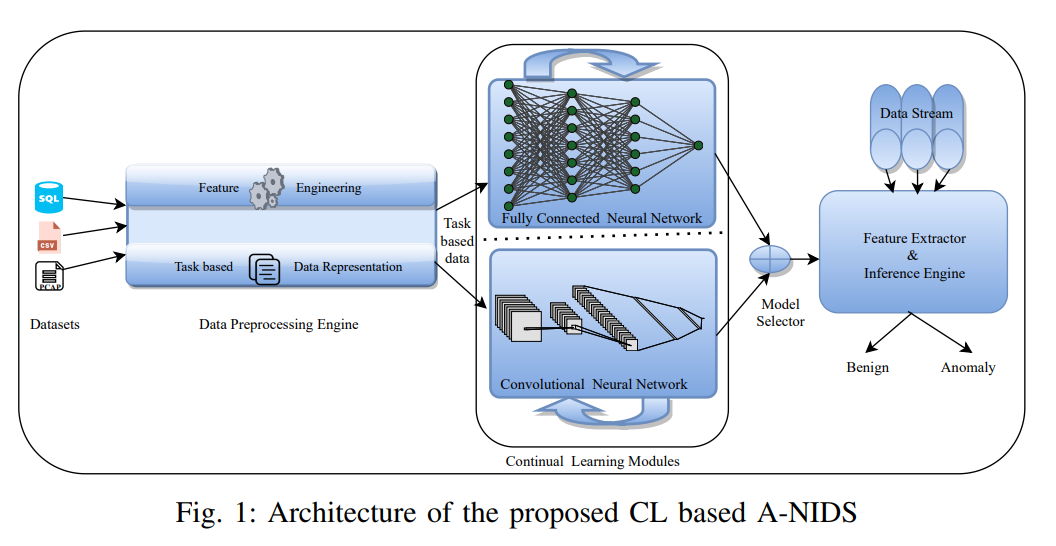
A. Data Preprocessing Engine
- Raw 네트워크 트래픽은 스트림에 도착하지만, CL 모델에서 직접 사용할 수 없음. feature 엔지니어링 기술을 통해 학습(테스트) 인스턴스로 변환되어야 함
- feature 엔지니어링 기술은 도메인 지식의 도움을 받아 풍부한 feature 집합을 선택하는 것을 도움
- 일반적으로 PCAP(Raw packet capture) 파일은 flow based statistical features로 변환되어 CL 알고리즘 사용을 위해 제공됨
- 모델의 학습 단계에서 하나 이상의 공격 클래스 학습 인스턴스가 작업 기반 표현으로 압축되고, 모델이 이 작업 데이터를 사용하여 순차적으로 학습됨
B. Continual Learning Modules
- CL 모듈은 제안된 ANIDS 시스템의 핵심 구성 요소, 일반적으로 모듈은 fully connected NN 또는 CNN을 사용하여 구축
- 침입 탐지는 간단한 경우에는 이진 분류 문제로, 복잡한 경우에는 다중 클래스 분류 문제로 공식화됨
- CL 모델의 구조적 이점은, 새로운 공격 데이터를 통합하는 동안 전체 학습 데이터가 필요로하지 않는 것
- 시스템에서 2개의 아키텍처, 2개의 CL 알고리즘 및 naive 알고리즘 (as baseline)을 사용함
- MLP 및 CNN을 사용하여 다양한 작업 순서에서 성능을 비교함(TABLE 1은 MLP, CNN 아키텍처)

- 두 가지 인기 있는 CL 알고리즘, 1. Elastic weight consolidation (EWC, 정규화 기반 접근 방식), 2. Gradient Episodic Memory(GEM, 재생 기반 접근 방식)이 실험에 사용되고, baseline은 Naive CL 알고리즘으로 설정
- EWC loss function

- GEM loss function
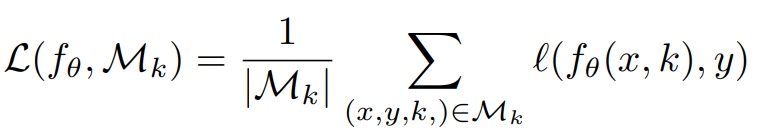
- GEM formulation

C. Inference Engie
- 스트리밍 방식으로 도착하는 네트워크 트래픽(데이터)은 2가지 새로운 과제를 안겨줌
- 1. 더 높은 데이터 처리량을 처리하는 방법 2. 즉시 기능을 추출하는 방법
- 더 많은 수의 스트림을 처리하는 가장 간단한 기술 중 하나는 일부 통계 측정을 사용하여 데이터를 균일하게 삭제하는 데이터 다운 샘플러를 사용하는 것
- 이러한 데이터 스트림을 처리하려면 가장 효율적이고 확장 가능한 feature 추출 도구가 필요
- 최고 성능의 CL 모델은 model selector 게이트웨이를 통해 정기적으로 IE에 배포됨
DATA PREPARATION FOR CL-BASED A-NIDS
- 이번 장에서는 사용된 데이터 세트와 CL based A-NIDS에 대해 데이터 준비가 수행된 방법에 대해 설명함
- 데이터 전처리 엔진 및 학습 모델의 기능은 1) Feature 엔지니어링, 2) 데이터 정규화 3) 작업 분할로 나뉨
A. Description of Datasets
- CICIDS2017 및 CSE-CICIDS2018은 Canadian Institute of Cybersecurity에서 만든 두 개의 다중 클래스 데이터 셋
- 이 두 데이터 세트에는 동일한 기능 세트가 있음; packet-based 및 양방향 흐름 기반 형식으로 추출됨
- 침입 탐지를 위한 다양하고 포괄적인 벤치마크 데이터 세트를 생성하기 위한 체계적인 접근 방식으로 개발되었기에 선택함
- KDD Cup'99는 1998년 MIT Lincoln Labs에서 준비하고 관리한 DARPA 침입 탐지 평가 프로그램에서 만든 가장 인기 있는 데이터 셋
- standard packet도 흐름 기반 형식도 아님
- 데이터 셋은 간단한 TCP 링크 속성과 로그인 실패 횟수와 같은 고급 속성이 포함, but IP 주소는 없음
B. Feature Engineering and Data Normalization
- 데이터 셋을 분석한 후, 특정 기능에 null 또는 inf 값이 있음이 발견 → 0으로 교체되었습니다.
- 두 데이터 세트의 중복 특성이 제거됨
- KDD'99 데이터 셋에서 service, is_host_login, num_outbound_cmds가 복잡성 및 계산 증가와 같은 문제를 일으킬 수 있으므로 제거됨
- scikit-learn의 레이블 인코더는 범주형 기능을 인코딩하는 데 사용됨
- 데이터 셋은 min-max 정규화를 사용, 0으로 나누는 오류를 피하기 위해 small ϵ가 추가됨
- CICIDS2017, CICIDS2018는 70개 feature, KDD Cup'99는 38개 feature이 데이터 정제 후에 남음
- CICIDS2017과 CICIDS2018에는 총 15개의 레이블이, KDD Cup'99에는 5개의 레이블이 있음
- 연구의 초점은 이진 분류이므로 모든 공격 클래스 레이블은 1로 인코딩, 양성 클래스는 0으로 인코딩

C. Task division
- CICIDS 데이터 셋은 5개의 작업으로 분할되며, 각 작업에는 3개의 클래스가 있음
- CICIDS2018 데이터셋은 83%를 양성 데이터로 포함
- 학습 프로세스에 대한 CI 효과를 이해하기 위해 클래스 0 데이터 샘플을 서로 다른 작업 간에 치환하여 5가지 작업 실행 순서를 만듦
- 각 작업 실행 순서는 순열 식별 번호(PID)로 고유하게 식별. 이 설정에서는 각 작업과 함께 새로운 클래스가 도입되므로(어떤 작업에서도 클래스가 반복되지 않음) 클래스 증분 학습(CIL) 설정이라고 함
- DIL(Domain Incremental Learning) 설정에서 양성(대부분) 클래스 샘플은 모든 작업에 분산되며 이상 클래스와 정상 클래스가 시간이 지남에 따라 임의의 순서로 발생하는 실제 시나리오를 나타냄
- 이를 달성하기 위해 클래스 0은 5개의 동일한 부분(15–19로 레이블 지정)으로 분할되고 5개의 작업에 분산됨
- 양성 클래스의 순열로 인해 다른 작업 순서는 다른 성능 결과(작업 순서당)를 초래할 수 있으며 이러한 동작을 TEOS(작업 실행 순서 민감도)라고 함. 학습 과정을 TEOS, 즉 작업 순서 불변에 robust하게 만들기 위해 CIL 및 DIL 설정과 관련하여 다양한 실험이 수행됨
PERFORMANCE RESULTS
이상적인 네트워크 데이터 셋은 실제 네트워크 트래픽 시나리오를 나타내므로 일반적으로 매우 불균형합니다. accuracy만을 지표로 선택하면 일관성 없는 결과가 나타납니다. 따라서 Precision, Recall 및 F1 score를 accuracy와 함께 눈에 띄는 metric으로 간주됩니다. 기존 metric 외에도 CL의 맥락에서 가장 유용한 메트릭인 REF(Relative Experience Forgetting)도 사용합니다. REF는 각 작업에 대해 별도로 계산됩니다.

정리: 정상과 이상이 불균형하기에 accuracy만을 지표로 삼기에는 무리가 있음 (모두 정상이라고하여도 accuracy가 높을 것이기 때문). 따라서 Precision, Recall, F1 score도 함께 사용 + CL 지표인 REF도 사용
A. Catastrophic Forgetting
- CF 문제는 1990년대 초에 다층 네트워크에서 밝혀짐
- 새로운 입력으로부터 학습할 때 이전에 학습한 지식을 모두 잊어버리는 경향이 있으며 이러한 망각은 공유된 가중치 공간 때문일 수 있음
- French는 CF는 다양한 작업의 내부 프레젠테이션 간의 과도한 중복으로 인해 발생한다고 주장
- CF를 극복하기 위해 모델은, 1. 학습된 지식을 새로운 입력으로부터 간섭을 방지하는 능력(안정성) 2. 새로운 입력에 대한 새로운 지식을 학습하는 능력(가소성)을 가져야 함
B. TEOS in CIL setting
CIL 설정에서는 모든 작업에서 학습 시간 동안 새로운 클래스가 도입되고 이 라인에서 계속해서 여러 작업 명령이 생성됩니다. CICIDS2017, 2018 및 KDD Cup'99 데이터 셋을 사용하여 TEOS를 조사했습니다. 두 가지 다른 아키텍처(MLP, CNN)는 naive, EWC, GEM 알고리즘과 결합되어 소개된 데이터 셋으로 학습합니다.


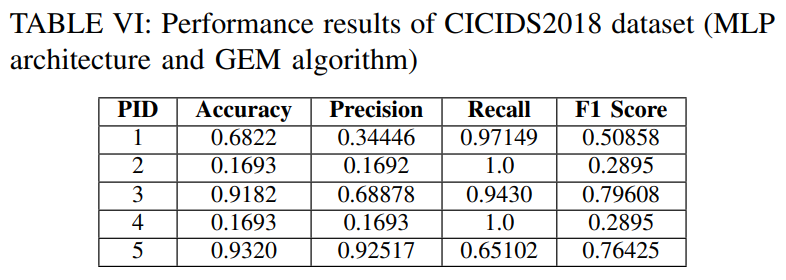
위의 결과에서 관찰한 주요 내용입니다.
- Accuracy 및 precision 값은 naive 알고리즘과 GEM 알고리즘에서 PID 1-4에 대해 낮음. 이는 공유 가중치 공간 값의 빈번한 변경으로 인해 발생할 수 있음
- 양성 클래스는 PID 1-4에 대한 이전 작업에 도입, 마지막 작업에는 이러한 PID에 대한 이상 클래스만 포함되어 있음
- 이상 데이터는 양성 데이터에 대해 이전에 학습한 지식을 방해하므로 모델은 양성 클래스에서 얻은 지식을 잊어버림. 결과적으로 모든 테스트 샘플은 이상으로 표시되므로 이러한 PID에 대한 recall이 높음
- PID 5의 경우 양성 클래스는 마지막 작업에서 사용할 수 있으며, 앞서 언급한 유사한 이유로 모델이 이상 클래스에 대한 지식을 유지할 수 없음. 따라서 이 PID에 대한 accuracy, precision 값은 높고 recall 값은 낮음
정리: PID 1-4는 양성 클래스에 대한 지식 x, PID 5는 이상 클래스에 대한 지식 x

- PID 1, 3 , 5에 관한 GEM 알고리즘은 naive & EWC와 비교하여 더 나은 결과를 보임. 샘플의 하위 집합이 저장되는 보조 메모리가 있기 때문
- 예를 들어 작업 1의 양성 클래스를 포함하는 PID 1을 보면, naive 및 EWC 알고리즘에서 PID 1은 작업 2(REF(t1,t2)=0.6718)를 사용한 훈련 직후, 양성 클래스의 지식을 잊어버리고 후속 작업에서 계속해서 성능이 저하됨. 반대로, GEM에서 PID 1의 경우 잊는 경험의 비율은 낮습니다. 즉, REF(t1,t2)=0.0208임
- 이전 연구 결과와 대조적으로, PID 2에 대한 GEM 알고리즘의 성능은 naive 및 EWC보다 우수하지 않음
- 이러한 행동에 대한 구체적인 원인을 파악할 필요가 있음
- 한 가지 가능한 방향은 정기적으로 잊어버리기 쉬운 이전 작업의 샘플을 저장하는 적응형 메모리 채우기 기술을 사용하는 것. Suresh는 CIL 설정이 있는 CICIDS2017 데이터 세트에서 CBRS(Class Balancing Reservoir Sampling)로 알려진 메모리 채우기 기술을 사용하여 더 나은 성능 결과를 보고함
- 다른 잠재적인 방향은 다른 작업 순서의 공식을 다시 검토하는 것. 우리는 이 작업에서 PID 2의 클래스 순서를 교환하여 이 전략을 탐색하므로 새로운 작업 순서 PID 2.1(표 VII 참조)이 형성
- PID 2.1의 망각은 꾸준히 감소하고 성능 결과가 향상됨


정리: PID 1, 3에서 GEM이 우수함. 그러나 PID 2에서는 그렇지 않음 → CBRS로 성능 향상, 클래스 순서 교환으로 성능향상 시도
*REF는 작을수록 좋은듯

- CICIDS2017에서 볼 수 있는 TEOS를 디코딩하려는 시도에서 PID 2를 고려했으며 이 순서는 성능이 가장 낮음
- 클래스 분리를 위한 t-SNE 플롯은 GEM 알고리즘 및 CICIDS2017 인스턴스가 있는 MLP 아키텍처의 두 번째 활성화 계층을 사용하여 그려짐
- 작업 2에서 양성 클래스가 도착하자 방향 및 결정 표면에 급격한 변화가 있음을 확인(5b)
- 작업 3에서 결정 표면이 복구되었음에도 불구하고 이 작업 순서는 가장 낮은 성능을 나타냄. 실질적으로 성능 저하의 원인은 모델의 매개변수가 작업 2를 학습한 후 학습을 중단하기 때문

- KDD Cup'99 데이터셋에서 가장 많은 샘플(데이터 포인트 3883370개)을 가지고 있기에, 작업 전반에 걸쳐 DoS 공격을 배치하여 실험을 수행
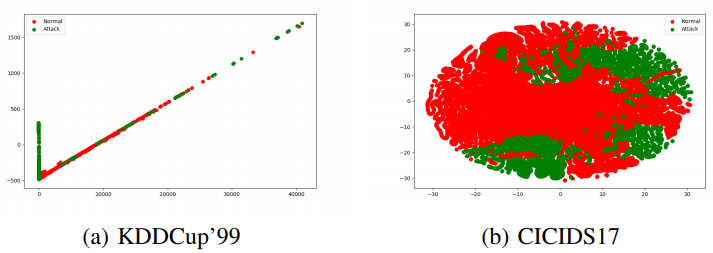
- CICIDS2017에 비해 KDD Cup'99의 클래스 구분이 상당히 단순함을 알 수 있음
C. TEOS in DIL
DIL 설정에서 양성(다수) 클래스 데이터는 분할되어 모든 작업에 분산됩니다(표 IV 참조). 따라서 여기에 다른 작업 순열을 도입하는 것은 비효율적입니다. 이 설정에 대한 CICIDS2018 데이터 세트의 성능 결과는 표 X 및 표 XI에 나와있습니다.

- 이 설정의 성능은 향상됨
- 이에 대한 한 가지 설명은, 다양한 작업 순서 순열이 자연스럽게 회피되는 모든 작업에 걸쳐 균일한(수) 샘플이 존재한다는 것
- 따라서 TEOS는 실험 설정에 의해 간접적으로 회피됨

- 모든 작업에 걸쳐 양성 데이터가 안정적으로 존재하면, 학습된 이상 작업 지식의 내부 표현과 충돌이 발생
- 결과적으로 대부분의 이상 샘플은 양성으로 예측됨
- 이로 인해 naive 및 EWC 알고리즘은 더 높은 정확도 및 정밀도 값과 더 낮은 recall 값을 산출(그림 7 참조)
- 그러나 replay 기능이 있는 GEM 알고리즘은 이상 지식을 유지하고 더 나은 결과를 얻을 수 있었음
- 이러한 CL 모델은 제한된 데이터로 확장되기 때문에 가장 확장 가능한 솔루션 중 하나
DIL 설정으로 성능 향상에 대한 가설을 강화하기 위해, 훈련 샘플 저장을 위한 보조 메모리(AM)가 있는 CBRS를 포함하도록 실험을 확장했습니다. CBRS는 가중치 replay(WR) 샘플 교체 전략을 사용하여 소수 샘플에 높은 우선 순위를 할당하여 AM에서 더 오랜 기간 동안 저장합니다. WR의 효과를 이해하기 위해 AM에서 다양한 클래스 샘플을 구성하는 방법에 대한 두 가지 정책을 시행합니다.

- 1. 전체 공격 등급 균형(WACB), AM에서 두 가지 유형의 클래스(양성 및 공격) 샘플을 처리
- 2. 각 개별 클래스는 IACB(Individual Attack Class Balance) 정책에서 개별적으로 처리됨
- 다양한 AM 크기(그림 8 참조)로 실험을 구성하고 앞서 언급한 정책을 적용
- 우리는 WR이 더 높은 replay 확률을 이상 샘플(소수이기 때문에)에 할당하므로 이상 샘플이 replay에 반복적으로 사용됨을 발견
- 따라서 높은 recall(약 0.95)이 관찰됨, 이는 이상 클래스 샘플을 충실히 감지했음을 의미
- 그러나 이상 샘플의 과도한 replay로 인해 양성 샘플 탐지율의 일부가 구성되고 있습니다.
- 따라서 다수의 클래스를 \메모리 채우기 기술의 설계로 고려하면(헤비 CI) 전반적으로 더 높은 성능을 얻을 수 있음
CONCLUSIONS & FUTURE DIRECTIONS
- 증가하는 사이버 위협에 대처하기 위해, 네트워크 시스템에서 이상 탐지를 위한 스스로 적응 가능한 알고리즘이 필요
- 새로운 공격 패턴을 포함하는 악성 트래픽을 식별하기 위해, CL based A-NIDS를 설계하기 위한 아키텍처를 제안
- 제안된 아키텍처는 새로운 공격이 나타날 때마다 이전 학습 데이터에 액세스하지 않기 때문에 확장 가능한 솔루션임
- CIL 설정이 DIL보다 TEOS에 더 취약하고, 추가 DIL 설정이 실제 트래픽 패턴(양호한 패킷 + 이상 패킷)과 유사하다는 것을 확인
- 따라서 고급 메모리 채우기 전략과 결합된 DIL은 CL 기반 실용적인 A-NIDS를 구축하기 위한 적절한 선택임
- 향후 계획은 더 복잡한 아키텍처를 실험하고, 작업에 구애받지 않는 알고리즘을 개발하고, 인식 메모리 채우기 기술을 망각하는 경험을 개발하는 것



