본 게시글은 Unsupervised Learning Based On Artificial NeuralNetwork: A Review 정리글입니다.
개인적인 생각이 서술되어 있습니다. 잘못된 내용이 존재할 확률이 존재하기에 주의 바랍니다.
잘못된 내용, 오타는 지적해 주시면 감사하겠습니다.
Reference
Dike, H. U., Zhou, Y., Deveerasetty, K. K., & Wu, Q. (2018, October). Unsupervised learning based on artificial neural network: A review. In 2018 IEEE International Conference on Cyborg and Bionic Systems (CBS) (pp. 322-327). IEEE. / APA style
Abstract
- 인공 신경망(ANN)은 예측, knowledge discovery, 분류, 시계열 분석, 모델링 등, 수많은 분야에 효과적으로 적용
- ANN 학습은 지도 학습, 강화 학습, 비지도 학습으로 구분
- 지도 학습에는 몇 가지 한계 → 이는 비지도 학습으로 극복 가능
- 비지도 학습과 관련된 주요 문제는, 레이블이 지정되지 않은 데이터에서 숨겨진 구조를 찾는 방법
- 본 논문은 ANN 기반 비지도 학습의 훈련 / 학습에 대해 검토
- ANN 기반의 비지도 학습 환경에서 다수의 숨겨진 노드를 선택, 수정하는 방법에 대한 설명 제공
- 비지도 학습의 benefit, challenge 요약
INTRODUCTION
- ANN은 네트워크의 입력 신호와 출력 신호 사이의 연결을 평가하는 데 사용할 수 있음
- input layer, hidden layer, output layer로 구성
- input layer: 외부 환경과 상호 연결되며 신경망을 훈련하기 위한 조건을 동일하게 나타냄
- hidden layer: 입력 계층과 출력 계층 사이에 있는 계층. 입력 및 출력 계층에 없는 뉴런 포함
- output layer: 외부 대기에 대한 신호로 인식, 출력 뉴런의 양은 신경망이 실행해야 하는 작업과 동등할 것으로 예상

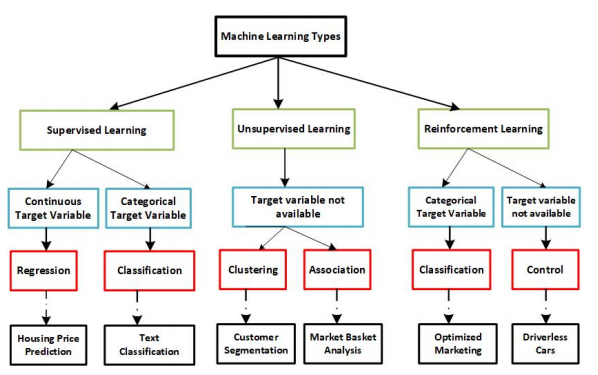
EXISTING MACHINES LEARNING TYPES
Supervised Learning

Reinforcement Learning
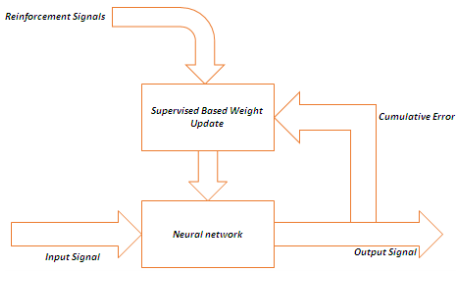
Unsupervised Learning

Overall structure
THE SELECTION AND FIXING NUMBER OF HIDDEN NODES
- 비지도 학습의 주요 문제는 레이블이 지정되지 않은 데이터에서 숨겨진 구조를 찾는 것
- 본 논문은 ANN 기반 비지도 학습에서 숨겨진 노드의 수를 선택하는 방법을 검토
- Hidden 뉴런 임의 선택으로, 네트워크에서 과소 적합 또는 과적합이 발생
- Hidden layer에 뉴런이 많거나 네트워크에 불필요한 뉴런이 있을 때 과적합이, 반대 상황에서는 과소 적합이 발생
- Hidden layer의 뉴런 수를 결정하는 것은 전체 신경망 설계를 정의하는 데 매우 중요한 부분
- Hidden layer의 hidden nodes 수를 찾는 방법은 다음과 같음
한 줄 정리: Hidden node 선택에 따라 과소 적합, 과적합이 발생할 수 있기에 적절한 선택이 중요
1. Try and Error Method
- 성공할때까지 반복적인 시도를 하는 방법으로, 두 가지 접근 방식이 있음
- Forward Approach: 이 접근법은 소량의 hidden 뉴런을 수집, NN을 훈련 및 검사하여, hidden 뉴런의 수를 꾸준히 줄이고 신경망을 test하기 위해 다시 train하는 것. 위의 절차는 train / test가 강화될 때까지 반복
- Backward Approach: Forward approach의 반대(엄청난 양의 hidden unit에서 시작). NN의 훈련과 테스트 후, NN의 훈련과 테스트가 반복되는 동안 숨겨진 뉴런의 합은 꾸준히 감소
한 줄 정리: Forward는 과소 적합 → 정상, Backward는 과적합 → 정상으로 향하는 방식
2. Rule of thumb method
- 경험적으로 습득한 방법. 예를 들어,
- a. hidden 뉴런의 합은 입력 계층의 크기와 출력 계층의 크기 배열에 있어야 함
- b. 그렇다면 숨겨진 뉴런의 합은 입력층과 출력층 크기의 2/3이어야 함
- c. 숨겨진 뉴런의 합은 입력층의 두 배 미만이어야 함
3. Two-phase method
- 1. trial and error method과 동일하지만 다른 방법
- 여기서 데이터 집합은 네 개의 집합으로 나뉘고, 네 집합 중 두 집합은 학습을 위해 첫 번째 단계에서 분리되고, 다른 집합은 두 번째 단계에서 시스템을 테스트하는 데 사용
- 그런 다음 데이터 집합의 마지막 그룹을 사용하여 교육 네트워크의 출력 값을 예측. 다양한 양의 뉴런이 숨겨진 층의 뉴런 수를 선택하는 데 가장 적은 수의 오류를 갖는 테스트가 반복
4. Sequential orthogonal approach
- 이 접근법은 hidden 뉴런을 차례로 추가하는 것
- 처음에는 오류가 충분히 작을 때까지 hidden 뉴런 수를 순차적으로 늘림
- 뉴런을 추가할 때, 이 뉴런에 의해 도입된 새로운 데이터는 이전에 추가된 hidden 뉴런의 출력 벡터가 차지하는 공간과 직교하는 출력 벡터의 일부에 의해 발생
- 이 방법의 또 다른 이점은 하이브리드 프로토타입을 개발하는 것
5. Network Growing and Network Pruning
- The growing 알고리즘은 네트워크 설계의 변경을 허용
- 작은 N으로 시작하여 많은 hidden 뉴런에 뉴런을 추가
- 단점은 hidden 뉴런의 수정을 약속하지 않고, 시간이 많이 소요된다는 것
BENEFITS AND CHALLENGES OF UNSUPERVISED LEARNING BASED ARTIFICIAL NEURAL NETWORK
Benefits
1. 측정에 대한 몇 가지 흥미로운 사항을 결정. 시스템은 선형성에 관계없이 모든 함수를 근사화할 수 있고, 이는 복잡한/추상적인 문제에 적합
2. 학습 과정은 관찰에서 더 추상적인 수준의 기호로 계층적으로 진행될 수 있음. 따라서 각 추가 계층은 한 단계만 학습하면 됨. 이 시스템은 hidden 노드를 찾는 능력을 가지고 있으며 입력 공간에 걸쳐 자신을 분산시켜 유사한 입력 벡터의 그룹을 인식하는 방법을 가지고 있음
3. 계층적 클러스터링 출력(K-값)에 대한 우수한 잠재력으로 supervision이 필요 x. 입력 관측치와 출력 관측치 사이의 간격을 연결하는 데도 사용할 수 있음
Challenges
1. 추가 계층 요구로 인해 한 번에 하나의 단계만 학습하므로 학습 시간은 모델 계층의 수준 수에서 선형적으로 증가
2. 군집 수(K-값) 예측이 어려움
3. 데이터의 지시는 최종 결과에 영향을 미침
4. outlier에 매우 민감



