본 게시글은 Modeling and Simulating Terrorist Networks in Social and Geospatial Dimensions 정리글입니다.
개인적인 생각이 서술되어 있습니다. 잘못된 내용이 존재할 확률이 존재하기에 주의 바랍니다.
잘못된 내용, 오타는 지적해 주시면 감사하겠습니다.
Reference
Moon, I. C., & Carley, K. M. (2007). Modeling and simulating terrorist networks in social and geospatial dimensions. IEEE Intelligent Systems, 22(5), 40-49. / APA style
Introduction
우리가 어디에 있는지는 우리가 아는 사람에게 영향을 미치며, 그 반대도 마찬가지입니다. 예를 들어, 회사가 직원들을 재배치할 때, 그들은 할당된 업무를 수행하는 동안 다른 사람들과 새로운 업무 관계를 발전시킵니다. 이론적으로는 회사의 실적은 향상될 것입니다.
그러나 성능은 또한 개인이 누구에게 무엇을 물어봐야 하는지 즉, 트랜잭션 메모리에 의존해야 하는지를 아는 것에 달려 있습니다. 이동은 트랜잭션 메모리와 정보가 흐르는 사회적 관계를 중단시킵니다. 따라서 사회적 분포와 지리적 분포가 동시에 변화할 때 성능이 향상될 수 있는지에 대한 의문이 제기됩니다.
사회적, 공간적 관계는 시간이 지남에 따라 진화합니다. 이들의 진화를 추정하는 것은 관리, 명령 및 제어 구조, 지능 분석 연구에 중요합니다. 분석가는 미래의 에이전트 사회적 및 공간적 분포를 파악하여 신생 리더, 핫스팟 및 조직 취약성을 식별할 수 있습니다. 역사적으로 이러한 추정은 subject-matter 전문가의 정성적 데이터 분석에 크게 의존해 왔습니다. 몇몇 연구자들은 다중 에이전트 모델과 시뮬레이션을 사용하여 이 문제에 접근했습니다.
이 연구는 소셜 네트워크의 변화가 미치는 영향과 지리공간적 변화의 영향이라는 두 가지 관점에서 이루어졌습니다. 두 관점 모두 신흥 조직 구조와 미래 성과의 측면을 투영할 수는 있지만, 물리적 운동과 사회적 운동 간의 상호작용을 검토할 수는 없습니다.
본 연구는 사회적 및 지리 공간 차원의 공진화 변화가 그룹 행동에 어떻게 영향을 미치는지 보여주기 위해 간단한 이론적 다중 에이전트 시뮬레이션 모델을 개발 및 본 연구의 모델은 고립된 사회 및 공간 모델의 한계를 극복합니다.
추론을 위한 모델의 잠재력을 설명하기 위해, 오픈 소스 텍스트에서 추출된 데이터를 사용하여 실제 테러리스트 네트워크에 대한 모델의 영향을 검토합니다. 전체 검증에는 추가 현장 데이터가 필요하지만, 모델의 출력은 대테러 영역을 넘어 적용되는 복잡한 조직 진화의 중요한 측면을 보여줍니다.
Input data set
모델의 입력은 사회적, 지리적 차원의 조직 구조 네트워크 표현이고, 여기에는 다음과 같은 지식과 작업 정보가 포함됩니다. 즉, 누가 무엇을 알고 누가 그 지식을 사용하고 있는지를 알 수 있습니다. 테러 네트워크의 경우 AutoMap 텍스트 분석 도구를 사용하여 기밀이 아닌 문서에서 관련 데이터를 추출했습니다.

- FIgure 1. a: 네 가지 노드 유형(에이전트, 지식, 작업 및 위치)으로 구성된 결과 네트워크의 전체적인 시각화
- FIgure 1. b: data set의 에이전트 대 에이전트(AA) 연결 시각화

- Table 1: 입력 네트워크의 인접 행렬 또는 메타매트릭스를 이들 노드에 걸쳐 보여줌
- 이 멀티모드, 멀티연결 네트워크 데이터는 우리 모델에서 조직의 현재 구조적 특성을 나타냄
- 본 연구는 두 에이전트 간의 상호 작용 확률을 지정하는 알고리즘을 사용하여 사회적 차원을 모델링
- 지리 공간 위치 네트워크의 data set에서 에이전트 이동을 해석하는 에이전트 재배치 메커니즘을 사용하여 지리 공간 차원을 모델링
- 예를 들어, 만약 두 에이전트가 상호작용이나 공식적인 관계를 가지고 있다면 그들 사이에 AA 연결이 존재한다고 가정
- 마찬가지로 에이전트가 지식 비트를 보유하고 있는 경우, 노드 간의 에이전트-지식(AK) 연결을 가정
- 두 위치가 동일한 컨텍스트에 나타나면 두 위치를 관련된 위치(LL)로 간주
- 이 위상 위치 네트워크는 에이전트 재배치 차원을 구성
- 에이전트-태스크 네트워크, 지식-위치 네트워크, 태스크-위치 네트워크와 같은 다른 하위 네트워크는 연결된 노드 유형과 데이터 코더의 관점에 기초하여 직관적인 의미를 가짐

- Figure 2. a: 에이전트-위치(AL) 네트워크를 보여줌
- Figure 2. b: 지리적 지도에 이 네트워크를 overlapping
Model summary
- 모델은 각 에이전트와 다른 에이전트와의 상호 작용을 시뮬레이션하여, 시간 경과에 따른 조직 성과 및 구조의 변화를 추정
- 에이전트가 상호 작용하고 학습함에 따라, 그들의 행동은 결국 성능과 구조를 변화
- 알고리즘은 에이전트 A의 동작에 대한 상호 작용 및 재배치 메커니즘을 개략적으로 설명
1. A는 VR(vision range) 내의 위치를 검색하여 알 수 없지만 필요한 지식 비트를 찾습니다.
2. A가 발견된 위치로 이동합니다.
3. A는 자신의 위치에서 미지의 지식을 배웁니다.
4. A는 통신 후보 자격을 갖춘 에이전트를 선택합니다.
5. A은(는) 선택한 에이전트와 미지의 지식을 교환합니다.
- 기본적으로 에이전트는 각 시뮬레이션 시간 단계에서 상호 작용하고 재배치할 수 있음
- 그들은 각 상호작용 및 재배치 기회에 대한 확률적 값에 따라 이동할 위치와 상호작용할 에이전트를 선택
- 정확히 어떤 에이전트가 어떤 에이전트와 상호 작용하는지, 언제 상호 작용하는지, 어떤 선택을 하는지, 그리고 그들이 소통하고 배우는 것은 확률적으로 정의됨
- 결과적으로 모델은 확률적이며, 안정적인 결과를 생성하고 결과 공간을 정의하기 위해 다중 복제가 필요

- Table 2: 에이전트의 행동과 네트워크의 진화 및 조직 구조를 주도하는 몇 가지 요인을 나열
- 예를 들어 에이전트 행동은 초기 환경을 설정하는 지정된 input data set에 따라 달라짐
- Input: 에이전트가 알고 있는 내용과 위치에 따라 에이전트 간의 초기 상호 작용 확률을 결정
- Parameters: 지리공간 차원의 재배치(이동) 반경, 사회적 차원의 상호작용(영향권) 반경, 에이전트와의 지식 교환 또는 특정 위치의 지식 수집 후 학습 확률 등
- Internal variables: 다양한 모델 공식에 따라 정의된 입력 및 매개 변수에서 계산된 동작을 반영
- 에이전트 상호 작용 및 재배치에서 중요한 파라미터를 다양화하여 모델을 테스트
- 먼저 에이전트 이동 반경(MR)을 0, 1, 2로 변경. 에이전트의 MR이 0이면 에이전트는 초기 위치에 고정, MR이 2인 경우 에이전트는 초기 위치에서 두 개의 LL 링크로 연결된 위치를 검색할 수 있음
- 다음으로, 확률 상호 작용에 기여하는 상대적 유사성(RS)과 상대적 전문성(RE)의 가중치를 변화
- RS 가중치가 높은 경우 에이전트는 주로 유사한 배경, 신념 및 지식을 공유하는 에이전트와 상호 작용, 이는 에이전트를 passive information receivers로 모방
- 대조적으로 RE 가중치가 높을수록 에이전트는 active information seekers가 활성화
- AA 또는 LL 네트워크에서 임의로 링크를 삭제하거나 추가함으로써 입력 데이터의 민감도를 테스트
한 줄 정리: MR, RS, RE, AA, LL 파라미터를 변경해 보며 모델을 테스트
Agent-interaction mechanism
- 에이전트는 각 period 동안 상호 작용할 기회가 있고, RS, RE, 사회적 거리(SD) 및 공간 근접(SP)의 네 가지 다른 요인의 가중 합인 상호 작용 확률 P에 따라 상호 작용할 에이전트를 선택
- 모델이 확률적이기에 에이전트는 일반적으로 선택할 가능성이 높은 에이전트를 선택하지만, 때때로 선택 가능성이 낮은 에이전트와도 상호 작용
- 따라서 이 모델은 의도와 행동 사이의 최적보다 낮은 연결뿐만 아니라 희귀한 예기치 않은 상호 작용을 반영하는 상호 작용을 포착
- 에이전트가 상호 작용할 다른 에이전트를 선택하면 두 에이전트는 지식 비트를 교환
- 교환된 각 지식 비트에 대해 모델은 0에서 1 사이의 균일한 분포에서 숫자를 그림
- 숫자가 수신 에이전트의 학습 속도 내에 있으면, 해당 에이전트는 AK 네트워크의 통신된 지식에 대한 새 링크를 갖게 됨
Relative similarity and relative expertise
- RS는 선택 및 선택당한 에이전트간의 지식 유사성을 반영하는 비율
- RS는 한 사람이 비슷한 교육, 신념, 인종을 공유하는 다른 사람과 상호 작용할 가능성이 증가하는 것을 설명하는, homophily(동족 선호)의 사회학적 원칙에 기초
- RS는 테러리스트가 같은 종교나 국적을 가진 다른 테러리스트들과 상호작용할 가능성을 나타냄
- RE는 선택당한 에이전트가 가지고 있는 지식 중, 선택한 에이전트가 가지고 있지 않은 지식의 양을 반영하는 비율, 트랜잭션 메모리를 기반으로 함
- RE는 중동 테러리스트가 무기 전문 지식이나 자금 출처에 대한 정보를 교환하기 위해 남미 마약 카르텔과 상호 작용하는 이유를 포착
- 언뜻 보기에는 두 가지 요소가 서로 모순되는 것처럼 보일 수 있지만, 그것들은 테러리스트의 지식 습득 태도의 다른 측면을 포착하는 두 가지 지표일 뿐
* K: # of knowledge bits

한 줄 정리: RS는 비슷한 집단 간의 관계를, RE는 다르지만 상호보완적인 집단 간의 관계를 보여줌
Social distance
- SD는 에이전트의 상호 작용 확률에 영향을 미치는 또 다른 요소로, 두 에이전트가 많은 소셜 링크를 통과해야 하는 경우 확률은 낮아야 하며, 그 반대의 경우도 마찬가지
- 두 에이전트 사이의 최단 경로를 찾은 다음, 하나를 해당 경로의 링크 수로 나누어 계산
- SD가 영향권인 SI의 최대 링크 수보다 클 경우, SD는 사회적 상호작용 경계 모델링을 위해 max+1로 설정
- 에이전트는 SI 경계 내에서 다른 에이전트의 근접성을 인식하고 구별할 수 있지만, 상호 작용하는 에이전트가 경계 외부에 있을 때 근접성을 구별할 수 없음
- 이 경우 에이전트는 실제 SD는 다를 수 있지만 상호 작용하는 에이전트를 SI + 1 링크만 있으면 됨

Spatial proximity
- 직관적으로, 같은 위치에 있는 두 사람이 다른 위치에 있는 두 사람보다 대화할 가능성이 높음
- SP가 인터넷 시대에는 유의미하지 않을 수 있다고 생각할 수 있지만, 테러리즘 영역에서는 같은 훈련소나 같은 모스크에 참석하는 것이 중요한 상호작용 지표
- SP 모델은 SD와 유사하지만 소셜 링크가 아닌 동일한 위치에 있을 확률을 나타냄
- SP가 지리공간 차원의 최대 통신 범위인 VR보다 크고 사용자가 선택한 경우, 모델은 계산 편의를 위해 SP = max + 1로 설정
- 지리공간 영역 계산에서 VR을 사용하는 근거는 사회적 차원에서 SI를 사용하는 근거와 같음

한 줄 정리: 사회적 차원(SI, SD), 지리적 차원(VR, SP)
Probability of interaction
- 설명한 네 가지 다른 요인으로 에이전트가 상호 작용할 다른 에이전트를 선택할 확률을 가중 합계로 표현
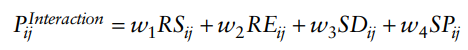
- 모델은 에이전트 쌍에 대한 확률을 계산할 수 있지만 SD와 SP라는 두 가지 거리에 따라 가능한 상호 작용 후보 에이전트의 수를 제한
- 이 제한은 한 사람이 이웃의 다른 사람들과 상호작용을 한다고 가정
- 에이전트는 후보 에이전트와만 소통가능하므로, 각 에이전트와 후보 에이전트 간의 상호 작용 확률이 계산
- 모델은 상호작용 후보 집합을 다음과 같이 정의
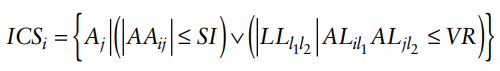
Agent-relocation mechanism
- 모델은 에이전트가 인접한 위치로 이동할 수 있게 해 줌
- MR 파라미터는 재배치 범위를 정의하지만 특정 위치를 선택할 확률은 더 복잡함
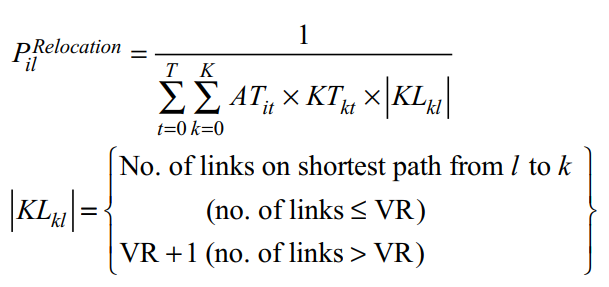
- 에이전트는 평균적으로 필요한 지식 비트에 대한 최단 경로를 보장하는 위치를 선택. 즉, 에이전트는 자신이 원하는 지식을 수집하기 위해 최적의 위치에 자신을 배치하려고 함
- 그러나 AA 상호작용 모델과 마찬가지로, 확률적으로 위치 선택을 결정하는 확률적 모델이기에 낮은 확률로 선호하지 않는 위치를 선택할 수 있음
위치를 선택한 후, 모델은 에이전트에서 이전 위치와의 edge를 제거하고, 새로운 위치와 edge를 추가하여 AL 네트워크를 변경 - 또한 에이전트는 VR의 위치에 연결된 지식 비트를 수집, 이 지식 수집은 다른 학습 속도를 사용한다는 점을 제외하면 에이전트 간의 지식 교환과 유사
- 이러한 지역적 지식 습득이 아니라고 주장할 수 있고, 특히 테러리스트들이 웹사이트로부터 새로운 지식을 배울 수 있는 현실 세계에서는 필연적인 사실
- 그러나, 많은 테러리스트들은 구체적이고 상세한 훈련을 받기 위해 훈련 장소와 조직 본부로 가기에, 이러한 이전은 대테러 분야에서 중요한 문제
Output measures
- 시간이 지남에 따라 진화하는 조직 평가를 위해 1. knowledge diffusion 2. energy task accuracy 성능 지표를 사용
- KD는 에이전트 간 지식 비트의 분산을 다음과 같이 측정
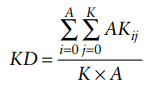
- But, KD는 아는 사람만 고려 → ETA는 에이전트가 할당된 작업을 수행하는데 필요한 지식을 얼마나 가지고 있는지 계산
- 이 계산은 agent-to-task(AT) 및 knowledge-to-task(KT) 네트워크를 도입
* KD: knowledge diffusion
* ETA: energy task accuracy
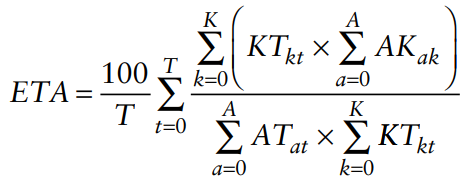
- 에이전트 및 위치에 대한 두 가지 중요도 메트릭을 정의
- 에이전트의 경우 시뮬레이션 중에 에이전트가 상호 작용하는 에이전트 수를 계산. 에이전트가 알고 영향을 미치는 에이전트 수를 나타냄
- 위치의 경우 종료 시 위치에 있는 에이전트 수를 계산. 더 많은 요원들이 있는 곳이라면 더 높은 테러 활동을 할 수 있음
Results
- 메타매트릭스 형식(Table 1)으로 테러 네트워크를 분석하고 에이전트 재배치, 지리공간 클러스터링, 에이전트 상호 작용 및 소셜 네트워크 진화에 대한 추정치를 생성하기 위해 모델을 사용
- 먼저 민감도 분석을 수행한 다음, 모델 출력을 2차원으로 시각화하고 분석
- 30개의 시뮬레이션 시간 단계에 대해 시뮬레이션을 세 번 반복
- 민감도 분석은 일부 독립적인 요인에서 유의한 p-value을 보여줌
- 구체적으로 MR은 ETA에 대한 중요한 예측 요소이고, KD와 지니 계수는 위치 임계 분포에 대해 중요하며, RS는 에이전트 임계 분포의 지니 계수를 설명하는데 중요
- p-value는 각 성능 메트릭에 대한 중요 요인을 식별하는 데 세 가지 복제로 충분하다는 것을 나타냄
* 지니 계수: 경제학에서 나온 용어로 모집단에 걸친 속성의 분포를 나타냄
Sensitivity analysis
- Table 3의 입력 파라미터를 변경하여 모델의 민감도를 분석
- 다양한 파라미터로 모델을 실행한 후 회귀 분석을 수행,
- 독립 변수는 MR, RS/RE 비율, 밀도로 구성
- 종속 변수는 두 가지 성능 메트릭과 에이전트 및 위치 임계 분포의 지니 계수
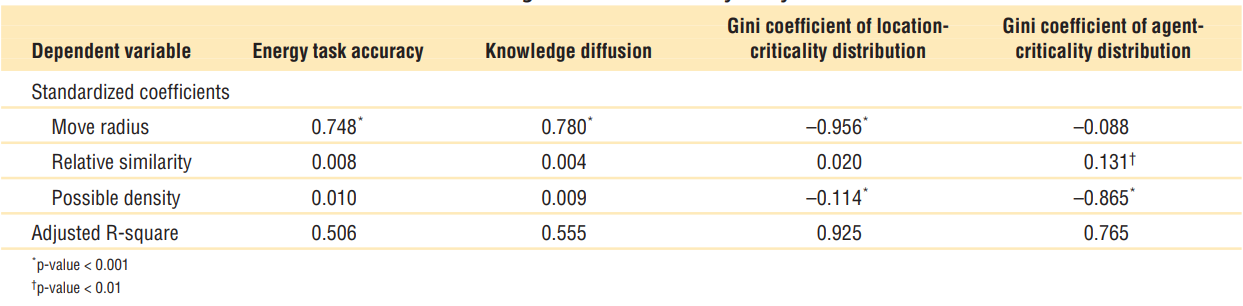
- Table 4는 회귀 분석 결과 첫째, MR이 증가함에 따라 네트워크의 성능이 향상. 모델에 등장하는 테러리스트들은 현재 위치에 머무르기보다는 더 많은 정보를 수집할 수 있는 지역으로 이동하는 경향이 있음. 또한 이러한 재배치는 정보 피드를 증가시켜 작업 성능을 향상
- 다음으로 MR과 가능한 밀도가 높을수록 위치 임계의 지니 계수가 감소. 이는 테러리스트들이 더 쉽게 이동할 수 있고 입력 네트워크가 더 촘촘해진다면 더 많은 테러리스트들이 분산될 것이라는 것을 의미
- 마지막으로, 낮은 RS는 더 중앙 집중화된 테러리스트 네트워크를 유도할 것. 특히, 입력 네트워크 밀도는 위치 중요도 분포에 대한 영향과 비교하여 에이전트 중요도 분포에 큰 영향을 미침
Location-criticality analysis
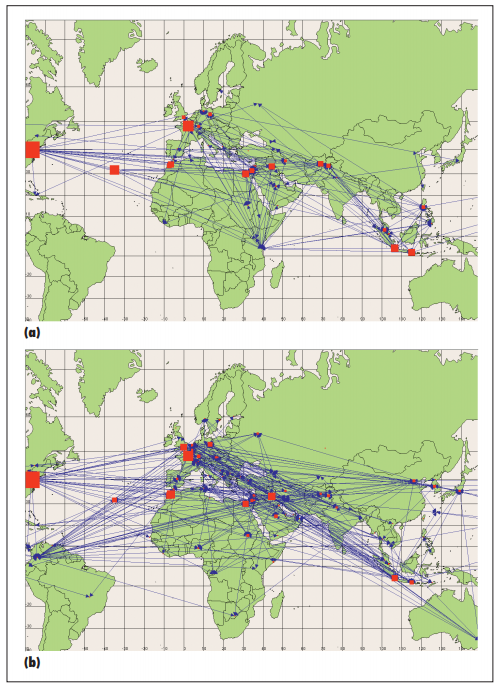
- Figure 3: 에이전트 이동은 시간이 지남에 따라 분리 패턴을 생성 * (a)가 시점 0, (b)가 시점 30
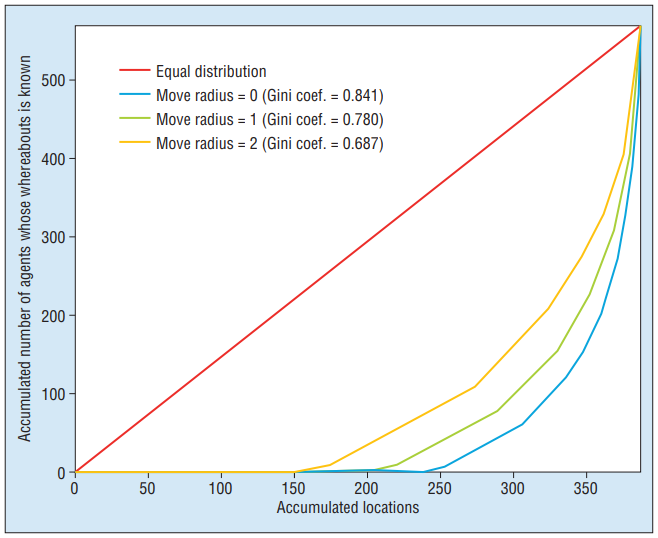
- Figure 4: 각 위치에 걸쳐 누적된 에이전트 분포를 보여주고, 이는 MR을 늘리면 에이전트들이 더 많이 분산될 것이라는 것을 암시
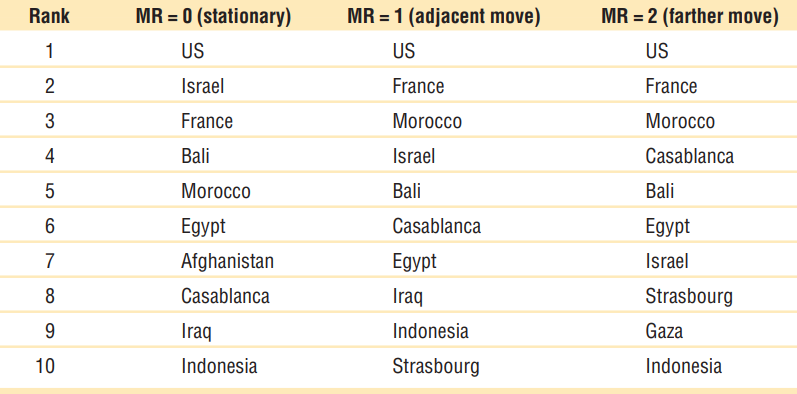
- Table 5: 시뮬레이션 후 테러리스트들이 은신하고 있는 상위 10개 장소를 나열
- Figure 4의 누적 분포와 지니 계수는 테러리스트 분산을 보여주었지만, 상위 10개 위치는 세 가지 MR 수준에서 상당히 일치
- 이는 테러가 빈번한 지역은 테러 활동이 적은 지역으로 relocation 하더라도, 여전히 테러가 빈번할 것임을 의미
- 북서 아프리카 지역(모로코와 카사블랑카)들은 일부 유럽 지역들처럼 중요한 위치를 차지
Agent-criticality analysis
- 중요한 에이전트를 분석, sensitivity analysis에 따르면 RS 변화는 에이전트 중요도의 분포에 영향을 끼침
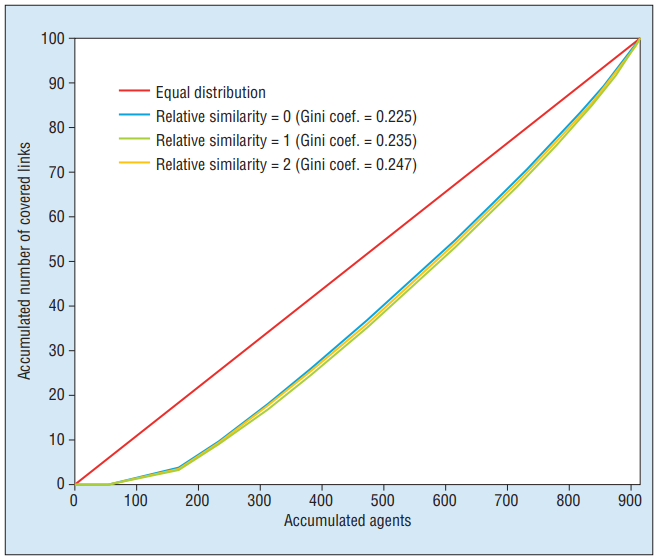
- Figure 5는 RS 레벨에 걸쳐 축적된 에이전트의 소셜 링크 커버리지를 시각화
- 지니계수 측면에서는 약간의 차이를 보이지만 링크 커버리지 분포는 크게 변하지 않음 → 테러 소셜네트워크의 진화가 매개변수 변화와 상관없이 안정적이라는 것을 의미
- 작은 변화이지만, RS가 높을수록 지니계수가 증가한다는 것 → 테러리스트들이 더 수동적으로 정보를 수집한다면 더 적은 수의 테러리스트들이 사회적 연결을 통제할 것임을 시사
- 예를 들어, 한 테러리스트 집단은 종종 다른 집단과 다른 배경을 가지고 있음. 그럴 경우 RS 상호작용 가중치가 강하면 두 그룹과 유사한 배경을 가진 테러리스트만이 그룹 구성원과 의사소통을 할 수 있게 됨.
- homophily 경향이 강하다는 것은 에이전트가 ICS 내에서 가능한 에이전트 수가 줄어들고 더 적은 에이전트가 더 많은 소셜 링크를 제어한다는 것을 의미
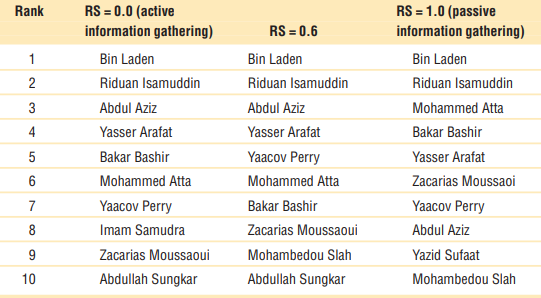
- 위치 중요도 분석과 마찬가지로 시뮬레이션 후 가장 많은 링크를 제어하는 상위 10명의 테러리스트를 식별
- Table 6: Bin Laden, Riduan Isamuddin과 같은 테러리스트들은 파라미터의 변화에도 불구하고, 여전함
- 그들은 이미 테러 소셜 네트워크의 중심이기 때문에 ICS에 자주 등장. 게다가, 그들은 꽤 포괄적인 배경과 지식을 가지고 있기 때문에, 대부분의 에이전트들은 최상위 에이전트들과 함께 높은 RS와 RE를 찾을 수 있음
- 반면, Mohammad Atta는 에이전트들과 공통적인 배경을 공유하였기에, 수동적인 정보 수집 가정 하에서 더 높은 순위를 보임
Conclusion
- 분석에 따르면 에이전트는 전 세계적으로 더 분산되지만 중요한 에이전트는 크게 바뀌지 않음
- 물론 분석 방법에는 한계가 있음
1. 시뮬레이션 모델을 검증(validation)하는 것은 매우 어려움
2. 입력 데이터 집합이 잘못되면 모형의 출력 방향이 잘못 지정될 수 있음.
- 몇 가지 우려에도 불구하고, 두 가지 이점은 실제 세계에서 모델을 사용하고, 향후 발견에 따라 모델을 업데이트하고 개발하기 위한 인센티브를 제공
1. 복잡한 다중 에이전트 모델은 정책 수립 및 이론 구축에 유용한 몇 가지 추정치를 생성
2. 또한 formula 기반의 에이전트 동작 설계는, 다른 결과를 이용할 수 있게 됨에 따라 쉽게 업데이트할 수 있음



