- 본 게시글은 김성훈 교수님의 '모두를 위한 RL강좌' 정리글입니다.
- 개인적인 공부를 위해 작성한 글이기에 강좌 외 내용이 추가되었을 수 있습니다.
- 잘못된 내용, 오타는 지적해 주시면 감사하겠습니다.
강의 및 슬라이드 링크:
Lecture 5: Q-learning in non-deterministic world
Deterministic은 확정적, 결정적이라는 뜻으로 매번 동일한 값을 반환한다.
반면에 Stochastic은 확률적이라는 뜻으로, 매번 다른 값을 반환한다.
현실은 Stochastic, 하기에 Lecture 5에서는 Stochastic을 고려하여 Q-learning을 보완한다.
Q가 왼쪽으로 가려다 오른쪽으로 우연히(Stochastic) 도달하여 성공했다고 가정해 보자. 하지만 Q는 왼쪽이 정답인 줄 착각하고 계속 왼쪽으로 향할 것이다. 그리곤 정답에 도달하지 못할 것이다.
그럼 어떻게 해야 정답에 가까워질 수 있을까?
Q의 말을 듣되, 약간만 참고하면 된다.
삶에서 멘토들의 말을 참고는 하되, 전적으로 따라 하지는 않는 것과 동일한 원리이다.

실현하는 방법은 Learning rate, alpha를 활용한다.
기존(Deterministic)에는 다음 Q 전체를 모두 활용하였다.(아래 그림 참조)
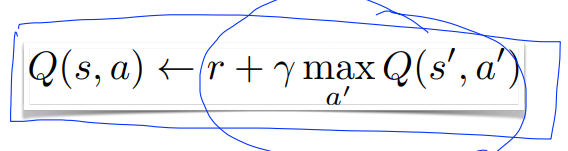
이 식을 Learning rate, alpha로, Q의 일부만 활용할 수 있다. 예를 들어 alpha=0.1로 설정하면 다음 Q의 일부만 활용가능하다.
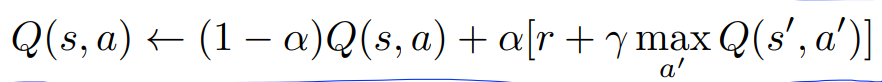
식을 alpha로 정리하면 다음처럼 정리가능하다.

앞선 강의에서 Convergence를 보였다.
Learning rate를 고려해도 여전히 Converge 할까?
여전히 Q_hat에서 Q로의 Convergence가 성립한다. (Watkins and Dayan, 1992)
Lecture 6: Q-Network
지금까지 Q-Table을 살펴보았다. 하지만 size가 커질수록 Q-Table의 연산량은 증가한다.
80x80 pixel과 2 color를 지닌 Q-Table의 연산량이 벌써 2**(80x80) 일 정도로 매우 크다. 즉, Q-Table은 현실적으로 활용하기 어렵다.
그럼 어떻게 할까? Network를 활용하면 된다.
Network는 Neural Network에서 살펴본 바와 동일한 구조이다.
(개념적인 부분에 집중하기 위해, 수식은 생략하고 넘어간다)

Neural Net에서도 Q_hat이 Q로 Converge 할까?
아니다.
Neural Net에서는 Diverge 한다.
실습을 통해 Q-network와 Q-table의 성능을 비교해 보아도 Diverge 하는 Q-network가, Converge 하는 Q-table보다 성능이 좋지 않음을 확인 가능하다.

그럼 쓸모가 없는 것인가?
아니다.
DeepMind에서 개발한 DQN을 활용하면 이 문제를 해결할 수 있고,
Lecture 7에서 살펴본다.
'공부 정리 > Reinforcement Learning' 카테고리의 다른 글
| 모두를 위한 RL강좌: Lecture 7 (1) | 2024.02.05 |
|---|---|
| 모두를 위한 RL강좌: Lecture 4 (0) | 2024.02.02 |
| 모두를 위한 RL강좌: Lecture 3 (0) | 2024.02.02 |
| 모두를 위한 RL강좌: Lecture 1, 2 (0) | 2024.02.02 |



