- 본 게시글은 김성훈 교수님의 '모두를 위한 RL강좌' 정리글입니다.
- 개인적인 공부를 위해 작성한 글이기에 강좌 외 내용이 추가되었을 수 있습니다.
- 잘못된 내용, 오타는 지적해 주시면 감사하겠습니다.
강의 및 슬라이드 링크:
Lecture 1: RL 수업소개 (Introduction)
위키 백과에서는 강화학습을 다음처럼 정의한다.
"강화 학습(reinforcement learning)은 기계 학습의 한 영역이다. 행동심리학에서 영감을 받았으며, 어떤 환경 안에서 정의된 에이전트가 현재의 상태를 인식하여, 선택 가능한 행동들 중 보상을 최대화하는 행동 혹은 행동 순서를 선택하는 방법이다."
1장에서는 강화학습에 대해 소개한다.
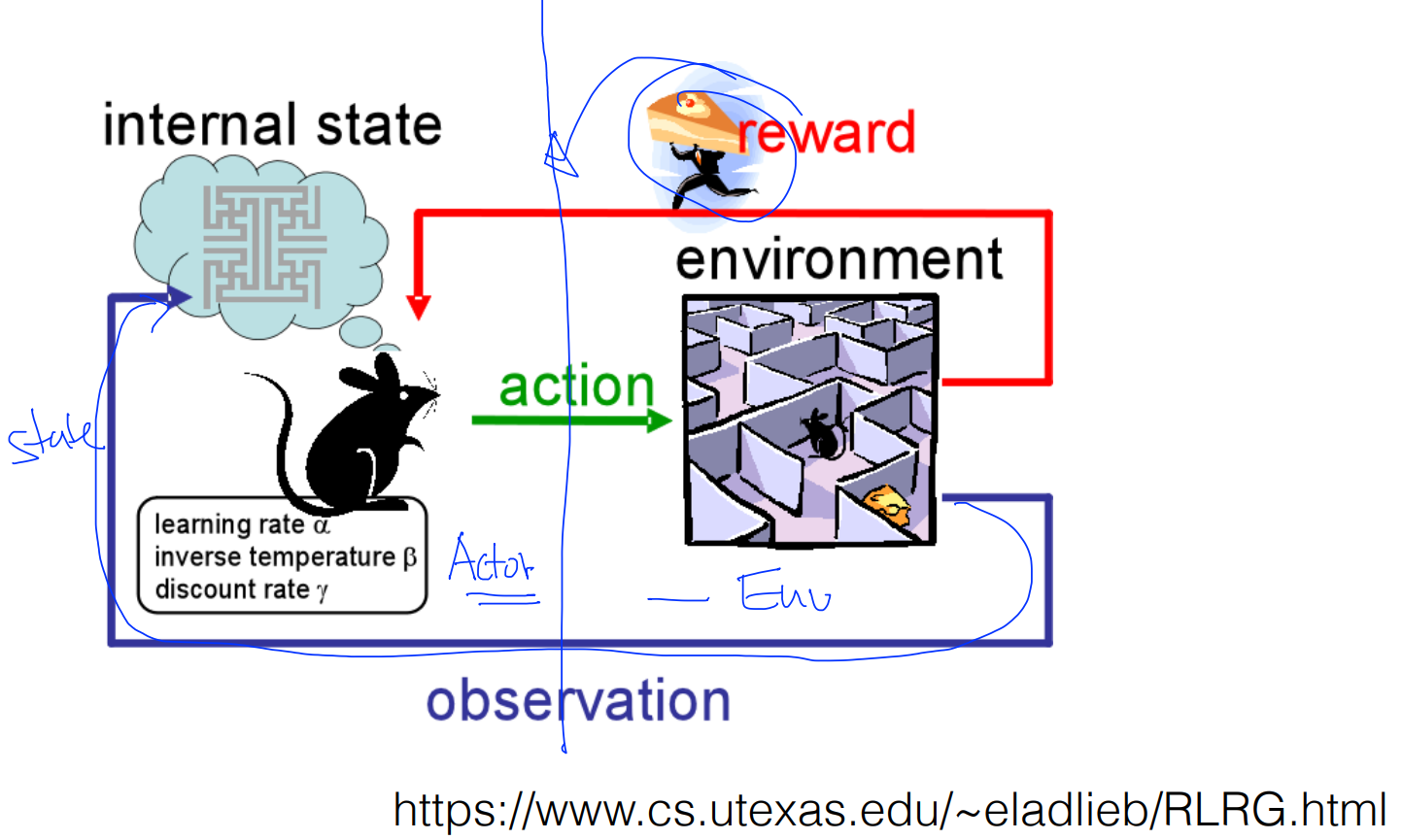
강화학습이 대중에 알려진 것은 비교적 최근이다.
벽돌 깨기 게임을 통해 우수한 성능이 알려지고, 알파고와 이세돌 9단의 바둑 대결(2016년)을 통해 본격적으로 각인되었다.
하지만 강화학습의 역사는 오래됐다.
1997년에 출판된 'MACHINE LEARNING'에도 강화학습이 존재한다.

강화학습 활용 분야는 Robotics, Business operations, Finance, E-commerce 등 매우 다양하다.
본 강좌는 수식 사용을 최소화하고, 예제를 통해 강화학습에 친숙하게 접근한다.
(참고로 강좌는 설명과 코드 강좌로 구성되어 있지만, 본 블로그는 설명에 초점을 둔다)
Lecture 2: Playing OpenAI GYM Games
OpenAI GYM에서 만든 Frozen Lake World를 통해 강화학습을 알아본다.
본 게임은 S에서 시작하여 G에 도달하면 성공하는 게임이다.
S에서 G로 가는 과정에서, F만 밟아야 하고, 만약 H를 밟는다면 실패하는 게임이다.
S에서 G로 도달하면 reward를 획득하고, reward를 최대화하는 방향으로 학습을 반복한다.
Agent가 Environment에 Action을 취하는 방법은 총 4가지(오른쪽, 왼쪽, 위, 아래)이다. Environment는 Action을 취할 때마다 state와 reward를 Agent에게 최신화해 준다.

다음과 같은 의문이 들 수 있다.
'정답이 나와있으니, 그저 따라가면 되는 것 아닌가..?'
하지만 Agent가 보는 환경에서는 어느 방향이 정답인지 알 수 없다.(아래그림처럼)
그렇기에 어려운 것이다.

'공부 정리 > Reinforcement Learning' 카테고리의 다른 글
| 모두를 위한 RL강좌: Lecture 7 (1) | 2024.02.05 |
|---|---|
| 모두를 위한 RL강좌: Lecture 5, 6 (0) | 2024.02.05 |
| 모두를 위한 RL강좌: Lecture 4 (0) | 2024.02.02 |
| 모두를 위한 RL강좌: Lecture 3 (0) | 2024.02.02 |



